

1-定量统计资料描述
在 SAS系统中,进行定量资料的统计描述最常用的两个过程是PROC MEANS和 PROC UNIVARIATE。
1.1 PROC MEANS
MEANS过程提供单个或多个变量的简单描述。和 UNIVARIATE过程相比,它更倾向于描述已经明确样本所在总体符合正态分布的变量,因此它不提供百分位数,但可以提供95%可信区间。同时在多个变量输出时,它的输出格式紧凑,便于阅读。 MEANS过程的语法格式如下。
PROC MEANS DATA=<选项>;
CLASS <变量名列>;
VAR <变量名列>;
BY <变量名列>;
FREQ <变量名>;
WEIGHT <变量名>;
ID <变量名列>;
OUTPUT OUT=数据集名 关键字= <新变量名列>... ;
语法说明如下。
- DATA语句指定要分析的数据集名及一些选项,它必须是原SAS数据集。
- CLASS语句指出分组变量,按变量名列分组统计,不要求数据集排序。
- VAR语句指出要分析的变量名列。
- BY语句指出分组变量,按变量名列分组统计,要求数据集已按变量名列排序。
- FREQ语句表明该变量为分析变量的频数。
- WEIGHT语句表明分析变量在统计时要按该变量权重。
- ID语句指明输出时加上该变量作为索引。
- OUTPUT语句指定统计量的输出数据集名(OUT=), 并指定统计量对应的新变量名(关键字=)。
MEANS过程中标准误的关键字是STDERR, 而 UNIVARIATE过程中为 : STDMEAN,另外LCLM和 UCLM这两个关键字也是UNIVARIATE过程所没有的。
1.2 PROC UNIVARIATE
UNIVARIATE过程对数值变量给出了比较详细的变量分布的描述,其中包括变量的极端值、常用的百分位数(包括四分位数和中位数)、用几个散点图描绘变量的分布、频数表和正态分布的检验等。 UNIVARIATE过程的语法格式如下。
PROC UNIVARIATE DATA=<数据集名> <options> ;
VAR <变量名列> ;
BY <变量名列> ;
FREQ <变量名> ;
WEIGHT <变量名>;
ID <变量名列>;
OUTPUT OUT=数据集名
关键字= <新变量名列>...
pctlpts= <百分位数, ...>
pctlpre= <新变量名列> ;
语法说明如下。
- DATA语句指定要分析的数据集名及一些选项,它必须是原SAS数据集。
- VAR语句指出要分析的变量名列。
- BY语句指出分组变量,按变量名列分组统计,要求数据集已按变量名列排序。
- FREQ语句表明该变量为分析变量的频数。
- WEIGHT语句表明分析变量在统计时要按该变量权重。
- ID语句指明输出时加上该变量作为索引。
- OUTPUT语句指定统计量的输出数据集名(OUT=) 、统计量对应的新变量名(关键字=)、需要的百分位数(pctlpts=) 和所需百分位数对应的输出变量名( pctlpre=) 等。
如果省略所有非必需的语句和选项,UNIVARIATE过程则按默认情况输出全部变量的全部常用统计量。
1.3 对数正态分布资料的统计描述
有些指标(变量)虽服从偏态分布,但经数据转换后可服从正态或近似正态分布,可按正态分布规律处理。其中经对数转换后服从正态分布的指标,被称为服从对数正态分布,服从对数正态分布的数据经对数转换后按正态分布规律来进行描述。
1.4 定量指标描述性分析的SAS统计分析报表
SAS统计分析功能强大,但由于其统计输出结果很多,内容十分丰富。我们常要从OUTPUT中用人工的方法挑出所需要的结果,工作十分麻烦,而且容易产生错误。为了输出一个简明的统计报表,使统计工作简化并减少人为转抄引起的错误,直接用系统产生最终的统计分析报表,不需要任何人为的中间加工处理。可在原文查看定量指标的SAS统计分析报表的宏程序。
2-t检验
2.1 单样本t检验
2.1.1 有原始数据的单样本t检验SAS程序
对样本均数和总体均数的差别,可以直接进行比较,也可以将其看成每个测量值和总体均数差 值的均数和0 的比较,均为单变量分析的形式,可以用前面介绍的两个执行描述性统计分析功能 的过程来完成。即用UNIVARIATE过程和MEANS过程分别进行分析的SAS编程实现方法。
- 以MEANS过程实现对单变量分布位置的t检验,只需在PROC MEANS语句后面添加t和probt 两个选项,SAS即可给出样本均数与0比较的t检验值和t分布曲线下该t值对应的双侧尾部面积。
- UNIVARIATE过程在默认状态下即可给出单变量分布位置的t检验结果
2.1.2 无原始数据的单样本t检验SAS程序
MEANS过程和UNIVARIATE过程针对的都是有原始数据的资料。如果没有原始数据,就需要根据t检验的计算公式和概率函数PROBT来获得单样本t检验的结果。
例如 例7- 4
data temp;
input uO ul s n;
t=(ul-uO)/ (s/sqrt(n));
v=n-1;
p=probt(t,v);
cards;
72 74.2 6.5 25
;
proc print;
run;
2.2 配对设计资料的t检验
上面已介绍了已知总体均数时的显著性检验方法,但有时我们并不知道总体均数,且医学数据资料中更为常见的是成对资料,若一批某病病人治疗前有某项测定记录,治疗后再次测定以观察疗效,这样,观察"例就有"对数据,这即是成对资料(也可对动物做成病理模型进行治疗实验,以收集类似的成对资料)。如果有两种处理要比较,将每一份标本分成两份各接受一种处理,这样观察到的一批数据也是成对资料。由于成对资料可控制个体差异使之较小,故检验效率是较高的。
在医学研究中,常用配对设计。配对设计主要有4种情况:同一受试对象处理前后的数据,同一受试对象两个部位的数据,同一样品用两种方法(仪器等)检验的结果,配对的两个受试对象分别接受两种处理后的数据。
2.2.1 有原始数据的配对设计的t检验分析实例
对于配对设计定量数据,我们可以采用TTEST过程进行统计分析。TTEST过程功能是对两组 数据的均数进行差别比较的t检验。 语法格式如下。
proc ttest data= <options>;
class 变量名称(分组变量);
paired variables;
var 变量名称(待分析的数值变量);
by 变量名称(分组变量);
run;
其中,PROC TTEST语句和CLASS (或 PAIRED) 语句是必需的,其余的语句可以省略,CLASS语句、VAR语句及BY语句之间的顺序可以任意。 CLASS语句所指定的分组变量是用来进行组间比较的,PAIRED语句专门用来进行配对t检验的数据分析,而 BY语句所指定的分组变量是用来将数据分为若干个更小的样本,以便SAS分别在各小样本内进行各自独立的处理。VAR语句引导所要进行比较的所有变量的列表,SAS将对VAR语句所引导的所有变量分别进行组间均数比较的t检验。
2.2.2 无原始数据的配对设计的t检验分析实例
无论是MEANS过程、UNIVARIATE过程,或者是TTEST过程,针对的都是有原始数据的资 料。如果没有原始数据,我们就需要根据配对t检验的计算公式和概率函数PROBT来获得配对t 检验的结果。
例如 例7-10
data temp;
input d s n;
t=d/(s/sqrt(n));
v=n-1;
p=probt(t,v);
cards;
0.625 0.78 8
;
proc print;
run;
2.3 两独立样本的t检验
在日常工作中,我们经常要比较某两组计量资料的均数间有无显著差别,如研究不同疗法的降 压效果或两种不同制剂对杀灭鼠体内钩虫的效果(条数)等。假若事先难以找到年龄、性别等条件完全一样的人(或动物)作配对比较,那么就不能求每对的差数,而只能先算出各组的均数,然后进行比较。两组例数可以相等,也可以稍有出入。检验的方法同样是先假定两组相应的总体均数相等,看两组均数实际相差与此假设是否靠近,近则把相差看成抽样误差表现,远到一定界限则认为由抽样误差造成这样大的相差的可能性实在太小,拒绝假设而接受H1,作出两总体不相等的结论。
2.3.1 有原始数据的两独立样本t检验分析实例
成组设计资料的t检验与单样本t检验和配对t检验情况不同,以上两种情况最终都可将待分析的变量转化为一个,并属于同一个组(即不涉及分组变量)。而成组资料虽然分析的是同一个变量,但要涉及不同组之间变量的比较,显然用只能检验样本分布位置的UNIVARIATE过程是无法完成工作的,这里所要用到的过程是TTEST过程。TTEST过程的功能是对两组数据的均数进行差别比较的t检验。
两个小样本均数比较的t检验有以下应用条件:两样本来自的总体均符合正态分布,两样本来自的总体方差齐。故在进行两小样本均数比较的:检验之前,要用方差齐性检验来推断两样本代表的总体方差是否相等,方差齐性检验的方法使用F检验,其原理是看较大样本方差与较小样本方差的商是否接近“1”。若接近“1”,则可认为两样本代表的总体方差齐。判断两样本来自的总体是否符合正态分布,可用正态性检验的方法。
若两样本来自的总体方差不齐,也不符合正态分布,对符合对数正态分布的资料可以用其几何均数进行t检验,对其他资料可以用t’检验或秩和检验进行分析。
例如 例7-1
data temp;
input group x@@;
cards;
1 134 1 146 1 104 1 119 1 124 1 161 1 107
1 83 1 113 1 129 1 97 1 123
2 70 2 118 2 101 2 85 2 107 2 132 2 94
proc ttest;
class group;
var x;
run;
2.3.2 无原始数据的两独立样本t检验分析实例
以上的TTEST过程都是针对有原始数据的资料。如果没有原始数据,我们就需要根据成组资 料 t检验的计算公式和概率函数PROBT来获得成组资料t检验的结果。
例如 例7-15
data temp;
input x1 x2 n1 n2 s1 s2;
sc=sqrt((1/n1+1/n2)*((n1-1)*s1**2+(n2-1)*s2**2)/(n1+n2-2));
t=(x2-x1)/sc;
v=n1+n2-2;
p=probt(t,v);
cards;
20.95 21.79 20 20 5.89 3.43
;
proc print;
run;
3-方差分析
方差分析解决问题的思路是:从所有观测值的总变差中分析出系统误差和随机误差,并用数量 表示。在一定意义下比较系统误差和随机误差,若两者的差别不大,说明试验条件的变化(因素水平的不同)对试验结果的影响不大;如果两者相差较大,且系统误差大的多,说明系统条件变化引出的误差不可忽视。
3.1 完全随机设计资料的方差分析
在 SAS系统中,一般利用PROC ANOVA过程和PROC GLM过程进行方差分析。
- PROC ANOVA过程一般只能用于平衡数据的方差分析。所谓平衡数据,指的是所有效应因子的交叉水平上的样本数相同,否则称为非平衡数据。它比PROC GLM过程的运行速度要快,要求的存储空间也要小一些。
- PROC GLM过程可用于平衡和非平衡数据的各种方差分析、协方差分析以及广义线性模型分析。
3.1.1 PROC ANOVA
ANOVA过程的语法格式如下。
PROC ANOVA < options >;
CLASS variables < / option >;
MODEL dependents=effects < / options >;
BY variables;
MEANS effects < / options>;
TEST < H=effects > E=effect;
REPEATED effects;
语法说明如下。
- CLASS语句指定分类变量,指定模型中的效应因子变量。
- MODEL定义拟合模型,给出模型中的因变量和效应变量的模型结构,并且通过特定的表达 式规定自变量的作用方式;如果没有指定任何自变量,则模型中仅包含常数项,此时检验的内容是因变量的均数是否为零;MODEL语句中指定的自变量必须是CLASS语句中声明过的分类变量,ANOVA过程不允许自变量中有连续型变量(数值变量),而因变量则必须是数值型变量。
- BY语句指定分组变量。
- MEANS语句计算和比较均值,指令系统输出这个语句中给出的每一个效应变量各个水平对应的因变量的均值,或几个效应变量交叉水平对应的因变量的均值,并且可以检验比较各个水平对应的均值之间的两两差异。
- TEST语句指定效应平方和和误差项,构建检验,进行裂区设计数据处理时需要。
- REPEATED语句指定模型中的重复测量因子(MODEL语句中存在有相同试验单位的重复测量的独立变量时),已检验相关因子效应,其中的变量名代表重复测量因素(如测量时间等),其后的水平数代表重复测量的次数。如果需指定重复测量各次的具体标识,可在其后按顺序列出,并用圆括号括起来。
3.1.2 PROC GLM
GLM过程的语法格式如下。
PROC GLM < options > ;
CLASS variables < / option > ;
MODEL dependents=effects < / options > ;
BY variables ;
MEANS effects < / options > ;
LSMEANS effects < / options >;
CONTRAST effects < / options >;
ESTIMATE effects < / options >;
TEST < H=effects > E=effeet ;
REPEATED effects;
语法说明如下。
- CLASS语句指定分类变量,指定模型中的效应因子变量。
- MODEL定义拟合模型,给出模型中的因变量和效应变量的模型结构。
- BY语句指定分组变量。
- MEANS语句计算和比较均值,指令系统输出这个语句中给出的每一个效应变量各个水平对应的因变量的均值,或几个效应变量交叉水平对应的因变量的均值,并且可以检验比较各个水平对应的均值之间的两两差异。
- LSMEANS语句是GLM过程步特有的语句,它的功能和MEANS语句类似,指令系统输出这个语句中给出的每一个效应变量各个水平对应的因变量的均值,或几个效应变量交叉水平对应的因变量的均值,并且可以检验比较各个水平对应的均值之间的两两差异。但 LSMEANS语句输出的均值不是算术均值,而是最小二乘均值。
- CONTRAST语句使你可以用自定义的方式进行假设检验,它必须出现在MODEL语句之后;如果用到MANOVA语句、REPEATED语句、RANDOM语句或TEST语句, CONTRAST语句则必须出现在这些语句之前;标记用来标识所进行的检验,用以标识的文字或符号需用单引号括起来;效应表达式用以指定假设检验的因素(组合),这些因素(组合)必须是MODEL语句中出现过的;效应表达式后面的常数向量用以指定相应因素(组合)各水平的值,在指定各水平的情况下进行相关因素的分析。
- ESTIMATE语句用于实现对线性方程的估计,它也必须出现在MODEL语句之后,使用的规则和CONTRAST语句基本相同。其中的语句元素的含义和用法也与CONTRAST语句相同。
- TEST语句指定效应平方和和误差项,构建检验,进行裂区设计数据处理时需要。
- REPEATED语句指定模型中的重复测量因子(MODEL语句中存在有相同试验单位的重复测量的独立变量时),已检验相关因子效应。
3.2 随机区组设计资料的方差分析
随机区组设计是根据"局部控制”和 “随机排列”的原理进行的。 例如将试验地按土壤肥力程 度等不同的性质,划分为等于重复次数的区组,使区组内环境差异最小,而区组间环境允许存在差异,每个区组即为一次完整的重复,区组内的各处理都独立地随机排列。这是随机排列设计中最常用、最基本的设计。 随机区组设计的优点是:设计简单,容易掌握;富于伸缩性,单因素、复因素以及综合试验等都可应用;能提供无偏的误差估计,在大区域试验中能有效地降低非处理因素等试验条件的单向差异,降低误差;对试验地的地形要求不严,只对每个区组内的非处理因素等试验条件要求尽量一致。因此,不同区组可分散设置在不同地段上。缺点是:这种设计方法不允许处理数太多。因为处理数多,区组必然增大,局部控制的效率会降低,所以处理数一般不要超过20个,最好在10个左右。
例如 例8-5
data temp;
do group=1 to 7;
do block=1 to 3;
input x@@;
output;
end;end;
cards;
45.48 44.73 44.25
43.33 42.94 43.10
43.72 42.26 43.25
44.26 44.65 44.10
43.73 43.25 41.22
43.15 43.78 44.00
41.14 43.43 42.21
;
proc anova;
class group block;
model x=group block;
Run;
3.3 拉丁方设计资料的方差分析
完全随机设计只涉及一个处理因素,随机区组设计涉及一个处理因素、一个区组因素(或称为配伍因素)。倘若实验研究涉及一个处理因素和两个控制因素,每个因素的类别数或水平数相等,此时可采用拉丁方设计来安排实验,将两个控制因素分别安排在拉丁方设计的行和列上。拉丁方设计的特点是处理数、重复数、行数、列数都相等。
3.4 析因设计资料的方差分析
前面介绍的单因素方差分析只涉及一个处理因素,该因素至少有两个水平,只是根据实验对象的属性和控制实验误差的需要,采用的实验设计方法有所不同。即完全随机设计、随机区组设计和拉丁方设计的处理因素没有变化,只是改变了设计的方法。在同样的实验条件下,通过改进实验设计方法可以大大提高实验的效率。
**在此之前介绍的各种试验设计方法,严格地说,它们仅适用于只有1个试验(或处理)因素的试验问题之中,其他因素都属于区组因数,即与试验因素无交互作用。**如果试验所涉及的处理因素的个数≥2 ,当各因素在试验中所处的地位基本平等,而且因素之间存在1 级 (即 2 因素之间)、2级 (即 3 因素之间)乃至更复杂的交互作用时,则需选用析因设计。
析因设计的缺点是当因素个数较多时( 3 个因素以上),所需实验单位数、处理组数、实验次 数和方差分析的计算量会剧增。
例如 例8-9
data temp;
do a=1 to 2;
do b=1 to 2;
input x@@;
output;
end;
end;
cards;
10 30 10 50
10 30 20 50
40 70 30 70
50 60 50 60
10 30 30 30
;
proc glm;
class a b;
model x=a b a*b;
lsmeans a b a*b/pdiff adjust=bon;
run;
3.5 正交试验设计资料的方差分析
当析因设计要求的实验次数太多时,一个非常自然的想法就是从析因设计的水平组合中选择一部分有代表性的水平组合进行试验,因此就出现了分式析因设计。但是对于试验设计知识较少的实际工作者来说,选择适当的分式析因设计还是比较困难的。
正交试验设计是研究多因素多水平的又一种设计方法,它是根据正交性从全面试验中挑选出部分有代表性的点进行试验,这些有代表性的点具备了 “均匀分散,齐整可比”的特点,正交试验设计是分式析因设计的主要方法,是一种高效率、快速、经济的实验设计方法。日本著名的统计学家田口玄一将正交试验选择的水平组合列成表格,称为正交表。
例如作一个3因素3水平的实验,按全面实验要求,须进行$3^3=27$种组合的实验,且尚未考虑每一组合的重复数。若按L9(3)3 正交表安排实验,只需作9次,按 L18(3)7 正交表,则需进行18次实验,显然大大地减少了工作量。因而正交试验设计在很多领域的研究中已经得到广泛的应用。
例如 例8-11
data temp;
input x a b c d @@;
cards;
86 1 1 1 1
95 1 1 2 2
91 1 2 1 2
94 1 2 2 1
91 2 1 1 2
96 2 1 2 1
83 2 2 1 1
88 2 2 2 2
;
proc anova;
class a b c d;
model x=a b c d a*b;
run;
3.6 重复测量资料的方差分析
重复测量是指对同一观察对象的同一观察指标在不同的时间点上进行多次测量,用于分析观察指标在不同时间上的变化规律。这类测量资料在医学研究中比较常见。
例如,药效分析中常分析给药后不同时间的疗效比较。在实际工作中,重复测量资料常被误作配对设计或随机单位组设计进行分析,不仅损失了重复测量数据所蕴含的信息,还容易得出错误的结论。由于同一受试对象在不同时点的观测值之间往往彼此不独立,存在某种程度的相关,因此不能满足常规统计方法所要求的独立性假定,使得其分析方法有别于一般的统计分析方法。
其设计与配对设计t检验的试验表达完全相同,但却是两种不同类型的设计,其区别如下。
- 配对设计中同一对子的两个试验单位可以随机分配处理,两个试验单位同期观察试验结果, 可以比较处理组间差别。前后测量设计不能同期观察试验结果。
- 配对t检验要求同一对子的两个试验单位的观察结果分别与差值相互独立,差值服从正态分 布。而前后测量设计前后两次测量的结果通常与差值不独立。
- 配对设计用平均差值推论处理作用,而前后测量设计除了分析平均差值外,还可以进行相 关回归分析。
重复测量设计大体有两类,一类是对每个人在同一时间不同因子组合间测量,另外一类是对每个人在不同时间点上重复。前者常见于裂区设计,而后者常见于经典试验设计,即包括前测,处理一次或几次后测的情况。后者比前者要多见。不论沿裂区方向还是沿时间点重复,个体内因子无一例外的都是重复测量因子。重复测量设计的特点是一定有个体内因子,但不一定有个体间因子。后者是不同处理组合或不同个体组。而且即使有不同组群(例如男性和女性),但人人都经历重复测量,而不是一组接受重复测量,另一组不接受。
具有重复测量的设计,即在给予某种处理后,在几个不同的时间点上从同一个受试对象(或样品)身上重复获得指标的观测值;有时是从同一个个体的不同部位(或组织)上重复获得指标的观测值。由于这种设计符合许多医学试验本身的特点,故在医学科研中应用的频率相当高。如果试验中共有K个试验因素,其中只有M个因素与重复测量有关,则称为具有M个重复测量的K因素设计。
在对重复测量资料进行方差分析时,除了要求样本是随机的,在处理的同一水平上观测是独立的,及每一水平的测定值都来自正态总体外,特别强调协方差的复合对称性或球形性。因此,在进行重复测量资料的方差分析前,应先对资料的协方差阵进行球形性检验。若满足球形性要求,则直接进行方差分析;不满足球形性要求,则需对与时间有关的F统计量分子、分母的自由度进行校正,以减少犯Ⅰ类错误的概率,或直接进行多变量方差分析。
对重复测量实验数据的方差分析,需考虑两个因素的影响,一个因素是处理分组,可通过施加干预和随机分组来实现;另一个因素是测量时间,由研究者根据专业知识和要求确定。因此,重复测量资料的变异可分解为处理因素、时间因素、处理和时间的交互作用、受试对象间的随机误差和重复测量的随机误差等5部分。
重复测量设计的优点是:每一个体作为自身的对照,克服了个体间的变异。分析时可更好地集中于处理效应,同时被试者间自身差异的问题不再存在。也就是减少了一个差异来源。重复测量设计的每一个体作为自身的对照,研究所需的个体相对较少,因此更加经济。
重复测量设计的缺点是:滞留效应,前面的处理效应有可能滞留到下一次的处理;潜隐效应,前面的处理效应有可能激活原本以前不活跃的效应;学习效应,由于是逐步熟悉实验,因此研究对象的反应能力有可能逐步得到提高。
SAS为具有重复测量设计资料提供了多元和一元两种方差分析方法。本质上只有一个指标,为何要把测自不同时间点上的数据看成是多元的呢?因为同一行上的数据重复测自同一个受试对象,它们之间往往有较高的相关性。为了有效地处理重复测量数据间的相关性,GLM过程使用了特定模型的多元方法。若使用一元分析方法,资料必须满足特定类型的协方差矩阵,称为H型协方差。若资料具有这种类型的协方差矩阵,则称此资料满足Huynh-Feldt条件(以下简称H-F条件)。 某资料是否满足此条件,可进行球性检验。在 SAS中,只要在REPEATED语句中加上选择项/PRINTE (样本含量不能太小),便可实现此检验。
重复测量资料在SAS中的分析处理稍显复杂,但掌握起来并不难,只是稍微费点脑子而已。对于重复测量资料的分析处理,我们应用较多的是单变量方差分析的一般线性模型方法。在 SAS数据格式中,重复测量资料同一观察单位在各测量点的测量值用一组变量来表示(如X₁、X₂…、Xₙ,计算时将这一组变量当做一个整体作为反应变量来处理。
例如 例8-12
data temp;
input type$ subject time1-time4;
cards;
1 1 1.431 1.519 1.477 1.364
1 2 1.385 1.562 1.459 1.372
1 3 1.473 1.487 1.612 1.414
1 4 1.452 1.535 1.537 1.403
1 5 1.371 1.469 1.268 1.296
2 6 1.257 0.976 0.725 0.578
2 7 1.232 0.934 0.828 0.609
2 8 1.298 1.036 0.813 0.512
2 9 1.216 1.247 0.694 0.579
2 10 1.275 0.942 0.675 0.621
;
proc glm;
class type;
model time1-time4=type /nouni;
repeated time 4 (24 48 72 96) /printe summary;
means type;
lsmeans type/stderr;
run;
3.7 协方差分析
在介绍医学试验设计时曾谈到,严格按试验设计的4项基本原则设计试验(科学可行性原则、对照与均衡性原则、随机性原则、可重复性原则),目的就是为了排除非处理因素的干扰和影响,使试验误差的估计降到最低限度,从而可以准确地获得处理因素的试验效应。但在某些实际问题中,有些因素在目前还不能控制或难以控制,如在动物饲养试验中,各组动物所增加的平均体重不仅仅与各种饲料营养价值高低有关,还与各动物的进食量有关,甚至与各动物的初始重量等因素及其交互作用都有关系。如果直接进行方差分析,会因为混杂因素的影响而无法得出正确的结论。
协方差分析是将回归分析与方差分析结合起来使用的一种分析方法。在这种分析中,先将定量的影响因素(即难以控制的因素)看做自变量,或称为协变量,建立因变量随自变量变化的回归方程,这样就可以利用回归方程把因变量的变化中受不易控制的定量因素的影响扣除掉,从而能够较合理地比较定性的影响因素处在不同水平下,经过回归分析手段修正以后的因变量的总体均数之间是否有显著性的差别,这就是协方差分析问题的基本思想。
协方差分析是把方差分析与回归分析结合起来的一种统计分析方法。它用于比较一个变量Y在一个或几个因素不同水平上的差异,但Y在受这些因素影响的同时,还受到另一个变量X的影响,而且X 变量的取值难以人为控制,不能作为方差分析中的一个因素处理。此时如果X与Y之间可以建立回归关系,则可用协方差分析的方法排除X对Y的影响,然后用方差分析的方法对各因素水平的差异进行统计推断。在协方差分析中,我们称Y为因变量,X为协变量,即在方差分析中用来校正因变量的数值型变量。
也许有人会问随机因素的影响也是不能人为控制的,为什么不能把X作为一种随机因素处理呢?这里的差异主要在于作为随机因素处理时,虽然每一水平的影响是不能人为控制的,但我们至少可以得到几个属于同一水平的重复,因此可以把它们分别用另一因素的不同水平处理。最后在进行方差分析时,我们才能排除这一随机因素的影响,对另一因素的各水平进行比较。
注意统计学知识背后的研究假设。
由于协方差分析的过程包含了对协变量影响是否存在及其大小等一系列统计检验与估计,它显然比对差值进行分析等方法有更广泛的适用范围,因此除非有明显的证据说明对差值进行分析的生物学假设是正确的,一般情况下还是应采用协方差分析的方法。在医学研究中,很多情况下都需要借助协方差分析来排除非处理因素的干扰,从而准确地估计处理因素的试验效应。
和方差分析一样,协方差分析也属于参数分析,因变量Y应当满足以下假设条件。
- 在效应因子的每一个水平上,因变量Y服从正态分布,且方差相等。
- 在效应因子的每一个水平上,因变量Y和协变量x呈线性关系,且斜率相同。
这两个假设条件都可以用SAS过程步来检验。检验方法如下。
- 用 UNIVARIATE过程步检验在效应因子的每一个水平上,因变量Y是否服从正态分布。
- 用 TTEST过程步(g=2) 或 DISCRIM过程步(g>2) 检验在效应因子的g 个水平上,因变量Y的方差齐性。
- 用 REG过程步检验在效应因子的每一个水平上,因变量Y和自变量x是否呈线性关系。
- 用 GLM过程步检验上述得到的g个回归方程的斜率是否相等。注意:所谓斜率是否相等, 等价于协变量x与效应因子的交互效应是否存在。如果交互效应有显著性意义,说明在效应因子的不同水平上,因变量Y随协变量x变化的趋势是相同的,即回归直线平行;否则说明在效应因子的 不同水平上,因变量Y随协变量x变化的趋势是不相同的,即回归直线不平行。
例如 例8-14
data temp;
do a=1 to 12;
do b=1 to 3;
input x y@@;
output;end;end;
cards;
256.9 27.0 260.3 32.0 544.7 160.3
271.6 41.7 271.1 47.1 481.2 96.1
210.2 25.0 214.7 36.7 418.9 114.6
300.1 52.0 300.1 65.0 556.6 134.8
262.2 14.5 269.7 39.0 394.5 76.3
304.4 48.8 307.5 37.9 426.6 72.8
272.4 48.0 278.9 51.5 416.1 99.4
248.2 9.5 256.2 26.7 549.9 133.7
242.8 37.0 240.8 41.0 580.5 147.0
342.9 56.5 340.7 61.3 608.3 165.8
356.9 76.0 356.3 102.1 559.6 169.8
198.2 9.2 199.2 8.1 371.9 54.3
;
proc sort;
by a;
run;
proc univariate normal; /*检验按因子A分组的正态性*/
var y;
by a;
run;
proc sort;
by b;
run;
proc univariate normal; /*检验按因子B分组的正态性*/
var y;
by b;
run;
proc discrim pool=test; /*检验按因子A分组的方程齐性*/
class a;
var y;
run;
proc discrim pool=test; /*检验按因子B分组的方程齐性*/
class b;
var y;
run;
proc sort;
by a;
run;
proc reg; /*检验按因子A分组的线性相关性*/
model y=x;
by a;
run;
proc sort;
by b;
run;
proc reg; /*检验按因子B分组的线性相关性*/
model y=x;
by b;
run;
proc glm; /*检验平行性*/
class a b;
model y=x a b x*a x*b;
run;
4-直线线性回归与相关分析
相关是解决客观事物或现象相互关系密切程度的问题,而回归则是用函数的形式表示出因果关系。**有相关不一定有因果关系;反之,有因果关系的,则一定有相关。**我们称“因”的变量叫因变量,习惯上用Y 表示。以横轴代表自变量X , 纵轴代表因变量Y。可以将一群观察事物的两种关系在坐标图上以P(X,Y) 的方法定位,作出一群散点图,便可在图上看出两者的关系。
相关分析和回归分析是研究现象之间相关关系的两种基本方法。所谓相关分析,就是用一个指标来表明现象间相互依存关系的密切程度。与函数关系不同,相关变量间的关系不能用函数关系精确表达,一个变量的取值不能由另一个变量唯一确定。当变量x取某个值时,变量y的取值可能有无数个,各观测点分布在直线周围。
相关分析和回归分析有着密切的联系,它们不仅具有共同的研究对象,而且在具体应用时常常必须相互补充。相关分析研究变量之间相关的方向和相关程度。但是相关分析不能指出变量间相互关系的具体形式,也无法从一个变量的变化来推测另一个变量的变化情况。回归分析则是研究变量之间相互关系的具体形式,它对具有相关关系的变量之间的数量联系进行测定,确定一个相关的数学方程,根据这个数学方程可以从已知量推测未知量,从而为估算和预测提供了一个重要的方法。
4.1 直线相关分析 PROC CORR
所谓相关分析,就是分析测定变量间相互依存关系的密切程度的统计方法。一般可以借助相关系数、相关表与相关图来进行相关分析。
- 按相关程度划分,可分为完全相关、不完全相关和不相关。
- 按相关方向划分,可分为正相关和负相关。
- 按相关的形式划分,可分为线形相关和非线形相关。
- 按变量多少划分,可分为单相关、复相关和偏相关。
在 SAS系统中进行直线相关分析的过程步是CORR过程。CORR过程存在于SAS的 base模块,可以计算Pearson积矩相关系数、Spearman秩相关系数、Kendall’s tau-b 统计量、Hoeffding’s 独立性分析统计量 D , 以及 Pearson、Spearman、Kendall等偏相关系数。另外,它还可对用于估计可靠性的Cronbach系数α进行计算。
Corr过程的语法格式如下。
PROC CORR<选项列表>;
BY <DESCENDING> 变量名-1<... <DESCENDING> 变量名-n> <NOTSORTED>;
FREQ 变量名;
PARTIAL 变量名(列表);
VAR 变量名(列表);
WEIGHT 变量名;
WITH 变量名(列表);
Proc corr语句标志corr过程的开始,其后的选项列表涉及的内容较多,控制着很多重要的功能。
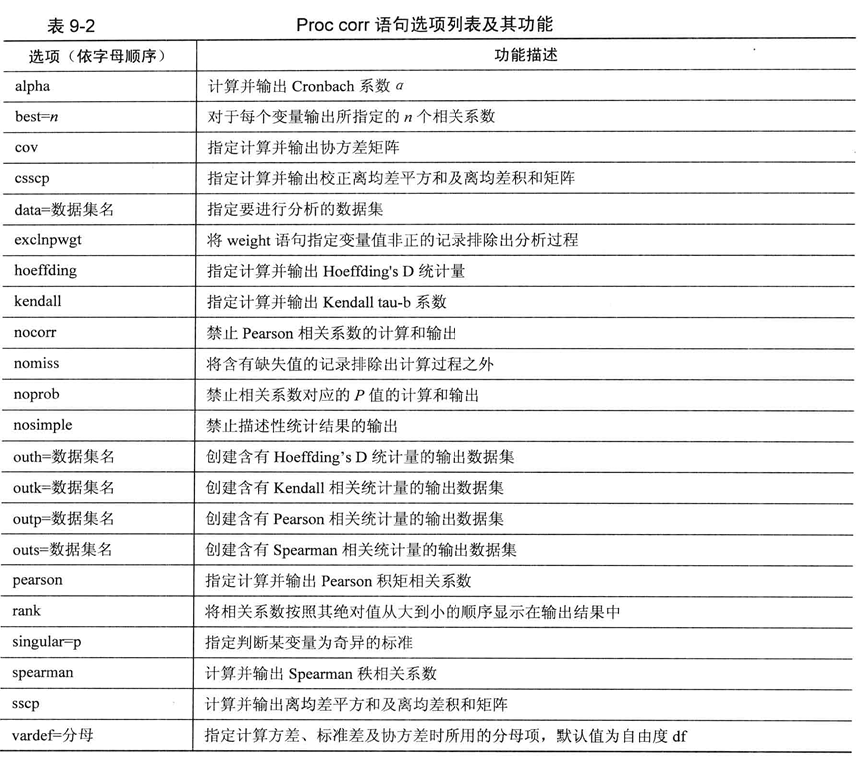
在CORR过程的几条语句中,BY语句、FREQ语句以及WEIGHT语句与以前介绍的过程中的完全相同。下面简要介绍其余的几条语句。
- PARTIAL语句:用以对所指定的变量计算偏相关系数或类似的偏统计量,可计算的偏统计量与PROC CORR语句中指定的选项有关。但其中只有Pearson积矩相关系数、Spearman秩相关系数及 KendalPs Tau-b可计算相应的偏统计量。
- VAR语句:VAR语句和其他过程中的也基本相同,这里的VAR语句指定的变量必须为数值型变量,至少应指定两个变量(当然只指定一个变量也可以计算,但是必须确定你确实需要证明“一个变量和它自身的相关系数为1” ),可同时指定多个变量,此时SAS会对任意两个变量之间进行相关分析。
- WITH语句:WITH语句用来指定和VAR语句指定的变量进行相关分析的变量。当有WITH语句存在时,VAR语句中指定的变量之间不再进行相关性分析,而其中的每个变量都和WITH语句指定的所有变量进行相关性分析,相关分析也不会发生在WITH语句所指定的变量之间。在输出结果的相关矩阵中,VAR语句指定的变量排列在行上,WITH语句指定的变量则排列在列上。如果需要,一个变量可以同时出现在VAR语句和WITH语句内。
- Pearson相关用于双变量正态分布的资料,其相关系数称为积矩相关系数。进行相关分析时, 我们一般会同时对两变量绘制散点图,以更直观地考察两变量之间的相互变化关系。
4.2 直线回归分析 PROC REG
直线回归分析的任务在于找出两个变量有依存关系的直线方程,以确定一条最接近于各实测点的直线,使各实测点与该线的纵向距离的平方和为最小。这个方程称为直线回归方程,据此方程描绘的直线就是回归直线。
直线回归是用直线回归方程表示两个数量变量间依存关系的统计分析方法,属于双变量分析的范畴。如果某一个变量随着另一个变量的变化而变化,并且它们的变化在直角坐标系中呈直线趋势,就可以用一个直线方程来定量地描述它们之间的数量依存关系,这就是直线回归分析。
直线回归分析中两个变量的地位不同,其中一个变量是依赖另一个变量而变化的,因此分别称为因变量和自变量,习惯上分别用y 和X来表示。其中X可以是规律变化的或人为选定的一些数值 (非随机变量),也可以是随机变量。
所谓回归分析,就是依据相关关系的具体形态,选择一个合适的数学模型,来近似地表达变量间的平均变化关系。
相关关系能说明现象间有无关系,但它不能说明一个现象发生一定量的变化时,另一个变量将会发生多大量的变化。也就是说,它不能说明两个变量之间的一般数量关系值。**回归分析,是指在相关分析的基础上,把变量之间的具体变动关系模型化,求出关系方程式,就是找出一个能够反映变量间变化关系的函数关系式,并据此进行估计和推算。**通过回归分析,可以将相关变量之间不确定、不规则的数量关系一般化、规范化,从而可以根据自变量的某一个给定值推断出因变量的可能值 (或估计值)。
回归分析包括多种类型,根据所涉及变量的多少不同,可分为简单回归和多元回归。简单回归又称一元回归,是指两个变量之间的回归。其中一个变量是自变量,另一个变量是因变量。
应用直线回归的注意事项如下.
- 作回归分析要有实际意义,不能对毫无关联的两种现象随意进行回归分析,;忽视事物现象间的内在联系和规律。
- 直线回归分析的资料,一般要求因变量Y是来自正态总体的随机变量,自:变量X 可以是正态随机变量,也可以是精确测量和严密控制的值。
- 进行回归分析时,应先绘制散点图。若提示有直线趋势存在,可作直线回归分析;若提示无明显线性趋势,则应根据散点分布类型选择合适的曲线模型,经数据变换后,化为线性回归来解决。
- 绘制散点图后,若出现一些特大特小的离群值(异常点),则应及时复核检查,对由于测定、记录或计算机录入的错误数据,应予以修正和剔除。
- 回归直线不要外延。直线回归的适用范围一般以自变量取值范围为限,在此范围内求出的估计值ŷ称为内插,超过自变量取值范围所计算的ŷ另称为外延。
REG过程只是SAS中众多关于回归的过程之一。REG是用于一般目的回归分析的过程,而其他过程则具有各自特殊的用途,REG过程涉及较多的语句和选项。 REG过程的语法格式如下。
PROC REG <选项列表>;
MODEL 应变量列表=<自变量列表></ 选项列表>;
BY 变量名列表;
FREQ 变量名;
ID 变量名列表;
VAR 变量名列表;
WEIGHT 变量名;
ADD 变量名列表;
DELETE 变量名列表;
MTEST <方程式<,...,方程式>></选项列表>;
OUTPUT <OUT=数据集名> keyword=变量名列表 <...keyword=变量名列表>;
PLOT <y变量名*x变量名> <=符号>;
<...y变量名*x变量名> <=符号> </选项列表>;
在REG过程的几条语句中,BY语句、FREQ语句以及WEIGHT语句与以前介绍的过程中的完全相同。下面简要介绍其余的几条语句。
- MODEL语句:用以指定所要拟合的回归模型。其最前面的标签为可选项,可以是不超过8个字符的字符串,用来对定义的模型进行标识,以便于在结果中分辨不同的模型,一般情况下系统会以默认的方式对模型进行标识,因此可以省略此项。关键字model后面所列的是模型表达式,和方差分析中anova过程的model语句相似。模型表达式中等号的左边为反应变量,等号的右边为自变量列表,自变量间以空格相分隔。这里所用到的所有变量必须存在于所分析的数据集中,而且是数值型的。如果要用到几个变量产生的综合变量,则必须在数据步完成新变量的创建过程,model语句中的组合型变量将被视为非法。
- ID语句:指定用以标识观测的变量。如果某一条 model语句指定了 cli、elm、p、r , 或者influence 选项,结果中会有针对每一条观测的输出,此时用id 语句指定每一条观测的标识将会使结果更易 于辨认或理解。如果没有id语句,SAS则用观测的编号来标识每一条观测。
- VAR语句:用来将那些未包括在model语句中,但需要将其包含在交叉积和矩阵中的数值型变 量。再在随后的add语句中想交互地加入模型的变量以及要在plot语句中对其绘制散点图的变量, 也需在var语句中列出。另外,如果只想利用proc reg语句后面的选项执行某些特定的功能,而并 不会用到model语句的话,var语句则是必需的。
- ADD语句:用以将自变量交互地加入模型,以考察某个变量对模型拟合的影响。此处用 到的变量必须为model语句或var语句中出现的变量,可以交互地加入某个变量到模型中,或者 将在delete语句中剔除的变量重新包含到模型中。对 add语句的每一次执行,都将改变模型的标签。
- MTEST语句:用以在有多个因变量时进行模型的多重检验。其最前面的标签项和model语句的 完全相同。语句中的方程式用以指定多重检验的假设模型,是一组以系数和变量名组成的线性方程式。此语句用在多元回归情况下,多个因变量对同一组自变量拟合线性模型时。
- OUTPUT语句:用于将回归分析中产生的结果输出到指定的数据集中,它所对应的是最后一个 model语句所定义的模型。在新产生的数据集中,包括输入数据集(用以进行回归分析的数据集) 的全部数据、回归分析过程中产生的各种统计量,以及针对每一观测的回归诊断指标数据等。但如果输入数据的类型为corr、cov或 ssep等,output语句则会失效。
- PLOT语句:用以对两个变量绘制散点图,表达式中位置在前(在乘号 " * " 之前)的变量作为 散点图的V轴,位置在后的变量作为散点图的X轴。等号后面的符号为散点图中表示点的图形符号,此项内容可省略,SAS会用默认方式显示图形,但如需指定,符号则要用单引号括起来。
5-多元线性回归与相关分析
在许多实际问题中,还会遇到一个随机变量与多个变量的相关关系问题,需要用多元回归分析的方法来解决,一元回归分析是其特殊情形。多元线性回归预测是用多元线性回归模型,多元回归模型就是在方程式中有两个或两个以上自变量的线性回归模型。
多元线性回归分析也称为复线性回归分析,它是一元线性回归分析或简单线性回归分析的推广,它研究的是一组自变量如何直接影响一个因变量。这里的自变量指的是能独立自由变化的变量,一般用x表示;因变量y指的是非独立的、受其他变量影响的变量,一般用y表示。由于多元线性 回归分析(包括一元线性回归分析)仅涉及一个因变量,所以有时也称为单变量线性回归分析。
具体地说,多元线性回归分析可以从统计意义上确定在消除了其他自变量的影响后,每一个自变量的变化是否引起因变量的变化,并且估计出在其他自变量固定不变的情况下,每个自变量对因变量的数值影响的大小。
在实际问题中,人们总是希望从对因变量y有影响的诸多变量中选择一些变量作为自变量,应用多元回归分析的方法建立“最优”回归方程,以便对因变量进行预报或控制,这就涉及自变量选择的问题。所谓“最优”回归方程,主要是指希望在回归方程中包含所有对因变量y影响显著的自变量,而不包含对y影响不显著的自变量的回归方程。
在回归方程中若漏掉对Y影响显著的自变量,那么建立的回归式用于预测时将会产生较大的偏差。但回归方程若包含的变量太多,且其中有些对Y的影响不大,显然这样的回归式不仅使用不方便,而且会影响预测的精度。因而选择合适的变量用于建立一个“最优“的回归方程,是一个十分重要的问题。
多元线性回归模型的参数估计,包括回归参数的最小二乘估计、拟合优度检验(包括总离差平方和分解、样本决定系数和调整后的样本决定系数)、模型显著性检验以及参数显著性检验。
选择"最优”回归方程的变量筛选法,包括逐步回归法、向前引入法和向后剔除法等。
- 向前引入法是从回归方程仅包括常数项开始,把自变量逐个引入回归方程。向前引入法有一个明显的缺点,就是由于各自变量可能存在着相互关系,因此后续变量的选入可能会使前面已选入的自变量变得不重要,这样最后得到的"最优”回归方程可包含一些对Y影响不大的自变量。
- 向后剔除法与向前引入法正好相反,首先将全部m 个自变量引入回归方程,然后逐个剔除对因变量Y作用不显著的自变量。向后剔除法的缺点在于:前面剔除的变量有可能因以后变量的剔除,变为相对重要的变量,这样最后得到的“最优”回归方程中有可能漏掉相对重要的变量。
- 逐步回归法是上述两个方法的综合。向前引入中被选入的变量,将一直保留在方程中。向后剔除法中被剔除的变量,将一直排除在外。这两种方程在某些情况下会得到不合理的结果。于是可以考虑,被选入的变量,当它的作用在新变量引入后变得微不足道时,可以将它删除;被剔除的变量,当它的作用在新变量引入情况下变得重要时,也可以将它重新选入回归方程。这样一种以向前引入法为主,变量可进可出的筛选变量的方法,称为逐步回归法。
回归分析是一种比较成熟的预测模型,也是在预测过程中使用较多的模型,在自然科学管理科学和社会经济中有着非常广泛的应用。但是经典的最小二乘估计,则必须满足一些假设条件,多重共线性就是其中的一种。实际上,解释变量间完全不相关的情形是非常少见的,大多数变量都在某种程度上存在着一定的共线性,而存在着共线性就会给模型带来许多不确定性的结果。
当存在严重的多重共线性时,会给回归系数的统计检验造成一定的困难,可能出现F 检验获得通过,T检验却不能够通过的情况。在自变量高度相关的情况下,估计系数的含义有可能与常识相反。在进行预测时,回归模型的建立是基于样本数据的,多重共线性也是指抽样的数据。如果把建立的回归模型用于预测,而多重共线性问题在预测区间仍然存在,则共线性问题对预测结果不会产生特别严重的影响。但是如果样本数据中的多重共线性发生了变化,则预测的结果就不能完全确定了。
检查和解决自变量之间的多重共线性,对多元线性回归分析来说是很必要和重要的一个步骤。
常用的共线性诊断方法有以下一些。
- 直观的判断方法
- 方差扩大因子法(VIF)
- 特征根判定法
多重共线性的处理方法一般有如下几种。
- 增加样本容量。
- 剔除一些不重要的解释变量。主要有向前法和后退法,以及逐步回归法。
- 不相关的系数法。
- 主成分法。
在学习一元线性回归分析时,讨论了与之紧密联系的一元相关分析或简单相关分析。将这个概念扩展到多元,就是多元相关分析或复相关分析。简单相关分析研究两个变量之间的关联性,复相关则是研究多个变量之间的关联性。
比较多元相关分析与多元回归分析,它们的相同点是都讨论了变量之间的关联性。区别是: ①多元回归分析给出了变量之间的依存关系,而多元相关分析却没有给出依存关系; ②多元回归分析要求将变量分为自变量和因变量,而多元相关分析不要求将变量分为自变量和因变量; ③多元回归分析分为自变量和因变量,要求因变量服从正态分布,而多元相关分析则要求所有的变量服从正态分布。
同样,比较多元相关分析与多元回归分析,有以下3对概念需要加以区别。
- 回归系数和相关系数。
- 偏回归系数和偏相关系数。
- 确定系数和复相关系数
5.1 多元线性回归方程的建立
多元线性回归分析在SAS系统中也是用PROC REG过程进行分析的,只是在一元线性回归分析的基础了多了一些选择项而已。此时回归模型的选择具有很大的灵活性。对于全部的自变量,可以将它们全部放在模型中,也可以只选择其中的一部分进行回归分析。而选择变量的途径也有多种,—般常用的有前进法、后退法以及逐步回归法。
例如 例10-1
data temp;
input x1 x2 x3 y;
cards;
51.3 73.6 36.4 2.99
48.9 83.9 34.0 3.11
42.8 78.3 31.0 1.91
55.0 77.1 31.0 2.63
45.3 81.7 30.0 2.86
45.3 74.8 32.0 1.91
51.4 73.7 36.5 2.98
53.8 79.4 37.0 3.28
49.0 72.6 30.1 2.52
53.9 79.5 37.1 3.27
48.8 83.8 33.9 3.10
52.6 88.4 38.0 3.28
42.7 78.2 30.9 1.92
52.5 88.3 38.1 3.27
55.1 77.2 31.1 2.64
45.2 81.6 30.2 2.85
51.4 78.3 36.5 3.16
48.7 72.5 30.0 2.51
51.3 78.2 36.4 3.15
45.2 74.7 32.1 1.92
;
proc reg;
model y=x1 x2 x3/tol vif collin selection=stepwise r;
run;
5.2 复相关系数与偏相关系数
复相关系数可以通过计算复确定系数,然后开平方根就可以计算出,即可以先通过REG过程获得复确定系数,然后算出复相关系数。但是,偏相关系数就只能通过CORR过程获得。
- 复相关系数是指在具有多元相关关系的变量中,用来测定因变量y与一组自变量y,x₁,x₂,…,xₘ 之间相关程度的指标。
- 偏相关系数度量了当其他变量固定不变时,或者说,消除了其他变量的影响之后,两个变量之间线性关联的强度
例如 例10-3
data temp;
input x1 x2 x3 x4 y;
cards;
51.3 73.6 36.4 2.99
48.9 83.9 34.0 3.11
42.8 78.3 31.0 1.91
55.0 77.1 31.0 2.63
45.3 81.7 30.0 2.86
45.3 74.8 32.0 1.91
51.4 73.7 36.5 2.98
53.8 79.4 37.0 3.28
49.0 72.6 30.1 2.52
53.9 79.5 37.1 3.27
48.8 83.8 33.9 3.10
52.6 88.4 38.0 3.28
42.7 78.2 30.9 1.92
52.5 88.3 38.1 3.27
55.1 77.2 31.1 2.64
45.2 81.6 30.2 2.85
51.4 78.3 36.5 3.16
48.7 72.5 30.0 2.51
51.3 78.2 36.4 3.15
45.2 74.7 32.1 1.92
;
proc corr;
var x1 x2 x3 x4 y;
run;
proc corr nosimple;
var x1 y;
partial x2 x3 x4;
run;
proc corr nosimple;
var x2 y;
partial x1 x3 x4;
run;
proc corr nosimple;
var x3 y;
partial x1 x2 x4;
run;
proc corr nosimple;
var x4 y;
partial x1 x2 x3;
run;
proc corr nosimple;
var x1 x2 x3 y;
partial x4;
run;
6-Logistic回归分析
线性回归模型和广义线性回归模型要求因变量是连续的正态分布变量,且自变量和因变量呈线性关系。当因变量是分类型变量,且自变量与因变量没有线性关系时,线性回归模型的假设条件就会遭到破坏。这时,最好的回归模型是Logistic回归模型,它对因变量的分布没有要求。从数学的 角度看,Logistic回归模型非常巧妙地避开了分类型变量的分布问题,补充完善了线性回归模型和 广义线性回归模型的缺陷。从医学研究的角度看,Logistic回归模型解决了一大批实际应用问题, 对医学的发展有着举足轻重的作用。
目前主要是用于流行病学研究中危险因素的筛选,但它同时具有良好的判别和预测功能,尤其是在资料类型不能满足Fisher判别和Bayes判别的条件时,更显示出Logistic回归判别的优势和效能。
一些实际问题不能直接用线性回归分析方法解决,其根本原因在于因变量是分类型变量,严重违背了线性回归分析对数据的假设条件。研究者将所研究的问题转换一个角度,不是直接分析y与x 的关系,而是分析y取某个值的概率P 与x 的关系。
分析因变量y取某个值的概率P与自变量x的关系,就是寻找一个连续函数,使得当x变化时,它对应的函数值P不超出[0,1]范围。数学上这样的函数是存在且不唯一的,Logistic回归模型就是满足这种要求的函数之一。与线性回归分析相似,Logistic回归分析的基本原理就是利用一组数据拟合一个Logistic回归模型,然后借助这个模型揭示总体中若干个自变量与一个因变量取某个值的概率之间的关系。具体地说,Logistic回归分析可以从统计意义上估计出在其他自变量固定不变的情况下,每个自变量对因变量取某个值的概率的数值影响的大小。
Logistic回归模型有条件与非条件之分,前者适用于配对病例对照资料的分析,后者适用于队列研究或非配对的病例一对照研究成组资料的分析。
6.1 非条件Logistic回归
Logistic回归分析在流行病学的病因研究中,是分析疾病与危险因素间联系的一种统计方法。在这类研究中,所观察的项目的值,常以二项反应变量取值,即生存与死亡,是否发病,是否接触危险因素等的反应变量y的取值是0或1。
所谓估计参数,就是根据收集到的X变量和y变量的观察值,估计回归系数和回归系数估计值的标准误。在 Logistic回归分析模型中,回归系数的估计方法通常是最大似然法。
一般来说,对于(A×C)表格对应的数据,由最大似然法得到的参数估计值往往不是非偏估计。为了得到一个非偏估计,需要采用重复递推的方法,将最大似然估计值不断修正。SAS系统使用的是重复加权最小二乘递推法来估计回归系数。
和线性回归分析一样,Logistic回归模型的回归系数是自变量对因变量作用大小的一种度量。 因为自变量的单位不同,不能用回归系数的估计值来判断哪一个自变量对因变量的影响作用最大。为了要进行比较,需要计算出标准回归系数。计算原理和线性回归分析一样。在标准回归系数的估计值中,绝对值最大的标准回归系数对应的自变量对因变量的影响最大。
模型的总体检验也称为拟合优度检验,对 Logistic回归模型的总体检验,常用方法有以下几个。这4 种用来检验模型总体拟合优度的统计量,在样本数足够大且无效假设成立时都逼进于一个卡方分布。其中,前两种校正了样本数和自变量个数,多在逐步回归过程中用来选择模型。
- AIC检验法:用于比较同一数据下的不同模型。AIC值越小,模型越合适。
- SC检验法:用于比较同一数据下的不同模型。SC值越小,模型越合适。
- 似然比检验法:用于检验全部自变量对因变量的联合作用。
- 计分检验法:用于检验全部自变量对因变量的联合作用。
为了正确说明疾病与危险因素的关系,就需要控制存在的混杂因素,Mantel-Haenszel分层分析的方法相当成功地解决了这一课题,但有其局限性,即随着控制因素的增加,分层越来越细时,每层的观察例数会越来越少,甚至会有零值出现,对相对危险度的估计带来了一定的困难或结果的不准确。非条件Logistic回归模型能克服这些不足之处,可以对危险因素的定量测定值进行分析,己经逐渐地被广泛应用。
在 SAS系统中,进行Logistic回归分析的过程步是PROC LOGISTIC过程。 LOGISTIC过程的语法格式如下。
PROC LOGISTIC data= /descending simple order= ;
Model 因变量=自变量/link= noint rsq cl rl selection= sle= sls= ;
freq 频数变量;
output out=pred=变量名;
run;
各语句选项的说明如下。
- DESCENDING:指令系统输出因变量取值由大到小的概率。默认时,系统输出因变量取值由小到大的概率。使用和不使用DESCENDING语句的回归模型的回归系数绝对值完全相同,但是符号完全相反。
- SIMPLE:指令系统输出每一个自变量的基本统计量。
- MODEL:给出模型的因变量和自变量。
- LINK:指定因变量概率函数的形式。
- NOINT:指令模型不含常数项。
- RSQ:指定输出确定系数。
- CL:指定输出参数估计值的可信区间。
- RL:指定输出相对危险度(或比数比)的可信区间。
- SELECTION, SLE和 SLS:和 REG过程步的对应选项一样,用于逐步回归分析。
- FREQ:是否使用,取决于数据的输入方法。当x和y变量的观察值被直接输入到SAS数据集时,不需要使用FREQ语句。但是,当x是分类型变量,且x和y变量的观察值不是直接输入到SAS数据集,而是将x和y变量的频数输入到SAS数据集中时,则需要使用FREQ语句。
- OUTPUT语句:用来保存指定的分析结果。Out选择项用来给出输出数据集的名字,Pred选择 项用来给出一个预测概率的变量名。
例如 例11-1
data temp;
do weight=750, 1150,1550;
do bpd=1,0;
input wt@@;
output;end;end;
cards;
49 19 18 62 9 66
;
proc logistic descending;
model bpd=weight/rsq cl;
weight wt;
run;
如果要分析两个连续自变量对因变量的交互影响,方法是建立一个新变量,它等于这两个连续自变量的乘积,然后放进模型中进行分析。它的结果仅显示交互影响是否存在,意义解释就不如OR简单易懂。
与多元线性回归分析类似,当自变量的数目较多时,为了使建立的Logistic回归模型比较稳定和便于解释,应尽可能地将回归效果显著的自变量选入模型中,作用不显著的自变量则排除在外。具体算法有前进法、后退法和逐步法等。Logistic逐步回归与线性逐步回归过程极为相似,但其中的检验统计量不再是F统计量,而是似然比统计量、Wald统计量和计分统计量之一。
6.2 条件Logistic回归
条件Logistic回归模型和非条件Logistic回归模型的区别在于:参数的估计是否用到了条件概率。
条件Logistic回归模型中参数的估计方法,也是采用最大似然估计法,参数 和模型的检验方法和非条件Logistic回归模型一样。
用于条件Logistic回归分析的过程步一般借用生存数据风险回归分析的PHREG过程步。使用 PHREG过程步时,要注意数据的输入方法和过程步语句的写法。
PHREG过程的语法格式如下。
Proc phreg data=;
Model 因变量*截尾变量=协变量/ ties=risklimits selection= sle= sls details;
Strata 分组变量;
Run;
其语句格式解释如下。
- MODEL语句:用于指定模型的结构,适用于生存时间有右截尾的情况,且生存时间变量作为模型的因变量,协变量作为模型的自变量。
- TIES:用来选择处理生存时间结点的方法,每一种方法使用了不同的公式来计算最大似然值。
- RISKLIMITS:指令输出危险比的95%置信区间,供选择的有:backward、forwards、stepwise、score。
- SLE:指定协变量进入模型的显著水平,缺省值是0.05。
- SLS:指定协变量停留在模型中的显著水平,缺省值是0.05。
- DETAILS:指令输出逐步回归过程中每一步的详细分析结果。
- STRATA:指定用于分组计算的分组变量。如果分组变量的数值不符合分组要求,则在变量后面的括号内列出分组的端点值。
例如 例11-6
data temp;
input id y x wt@@;
y=1-y;
cards;
1 1 1 3 1 0 1 3
2 1 0 5 2 0 1 5
3 1 1 14 3 0 0 14
4 1 0 62 4 0 0 62
;
proc phreg;
model y=x;
freq wt;
strata id;
run;
7-相对数(略)
8-行 × 列表分析(略)
9-非参数统计(略)
10-生存分析(略)
11-主成分分析
主成分分析也称主分量分析,旨在利用降维的思想,把多指标转化为少数几个综合指标。在实际问题研究中,为了全面、系统地分析问题,我们必须考虑众多影响因素。这些涉及的因素一般称为指标,在统计分析中也称为变量。因为每个变量都不同程度地反映了所研究问题的某些信息,并且指标之间有一定的相关性,因而所得的统计数据反映的信息在一定程度上有重叠。在用统计方法研究多变量问题时,变量太多会增加计算量和增加分析问题的复杂性,因而人们往往希望在进行定量分析的过程中,涉及的变量较少,得到的信息量较多。
在大部分实际问题中,变量之间是有一定的相关性的,人们自然希望找到较少的几个彼此不相关的综合指标,以尽可能多地反映原来众多变量的信息。选用几个“重要的”或 “有代表性”的指标来评价,就可能失去许多有用的信息,容易得出片面的结论。所以,我们需要一种综合性的分析方法,既可减少指标变量的个数,又尽量不损失原指标变量所包含的信息,对资料进行全面的综合分析。主成分分析正是适应这一要求产生的,是解决这类问题的理想工具。
主成分分析的基本思想就是将彼此相关的一组指标变量转化为彼此独立的一组新的指标变量,并用其中较少的几个新指标变量,综合反映原多个指标变量中所包含的主要信息,符合专业含义。何为主成分?简而言之,主成分实际上就是由原变量X₁〜Xₘ线性组合出来的m个互不相关、且未丢失任何信息的新变量,也称为综合变量。多指标的主成分分析常被用来寻找判断某种事物或现象的综合指标,并给综合指标所蕴藏的信息以恰当的解释,以便更深刻地揭示事物内在的规律。
主成分分析法是一种数学变换的方法,它把给定的一组相关变量通过线性变换转成另一组不相关的变量,这些新的变量按照方差依次递减的顺序排列。在数学变换中保持变量的总方差不变,使第一变量具有最大的方差,称为第一主成分,第二变量的方差次大,并且和第一变量不相关,称为第二主成分。依此类推,I个变量就有I个主成分。 主成分分析的方法步骤:对原始指标数据进行标准化变换、计算相关系数矩阵、计算相关矩阵的特征值和特征值所对应的特征向量、计算主成分贡献率及累计贡献率、确定主成分的个数、计算主成分载荷和计算主成分得分等。
研究多个指标变量之间的依存关系,是医学研究中很重要的一件事情。但是,在研究多个指标 变量之间的依存关系时,经常会遇到两个问题:①指标变量过多,使得分析的难度增加。②变量之间的共线性存在,即变量之间不完全独立,这种情况易造成分析结果不稳定或不正确。因此,解决自变量之间的多重共线性和减少变量个数对依存关系的分析就很重要了。
根据主成分分析原理,它一方面可以将k个不独立的指标变量通过线性变换变成k个相互独立的新量,这是解决多重共线性问题的一个重要方法。另一方面,主成分分析可以用较少的变量取代较多的不独立的原变量,减少分析中变量的个数。概括地说,主成分分析有以下几方面的应用。
- 对原始指标进行综合:主成分分析的主要作用是在基本保留原始指标信息的前提下,以互不相关的较少个数的综合指标来反映原来指标所提供的信息。
- 探索多个原始指标对个体特征的影响:对于多个原始指标,求出主成分后,可以利用因子载荷阵的结构,进一步探索各主成分与多个原始指标之间的相互关系,分析各原始指标对各主成分的影响作用。
- 对样本进行分类:求出主成分后,如果各主成分的专业意义较为明显,可以利用各样品的主成分得分来进行样品的分类。
在 SAS系统中,可利用PRINCOMP过程对数据进行主成分分析。 PRINCOMP过程的语法格式如下。
PROC PRINCOMP DATA= OUT= OUTSTAT= NOINT COV N STD VARDEF [选项];
VAR 变量/[选项];
PARTIAL 变量;
RUN;
各语句选项说明如下。
- DATA语句指定要分析的数据集名及一些选项,它可以是原SAS数据集,也可以是corr、cov、ucorr、ucov等矩阵。
- OUT选择项指定统计量的输出数据集名,该数据集保存的是样本的原始指标变量和主成分得分变量。
- OUTSTAT选择项指定输出结果的SAS数据集名,该数据集保存的是每一个指标的均值、标准差、样本数、相关系数矩阵、特征值和得分系数等。
- NOINT选择项指令系统使用未对均值校正的相关系数矩阵或方差协方差矩阵进行主成分分析,它等价于主成分模型中不含常数项。
- COV选择项指令系统用方差协方差矩阵计算主成分,如果该选择项缺省,系统则用相关系数矩阵计算主成分。
- N选择项给出主成分的个数。
- STD选择项指令系统在输出数据集中,主成分得分变量的方差被标准化为I。
- VAR语句用于列出要分析的原始变量。如果该语句缺省,系统则分析其他语句中未涉及的所有指标变量。
- PARTIAL语句用于列出混杂变量,指定系统使用偏相关系数或偏方差、协方差来计算主成分。 例如PARTIAL X它表示偏相关系数或偏方差、协方差是以变量X为混杂变量的,即所有的相关系数都表示的是在X不变的情况下,两个变量之间的关联程度。但是,该语句列出的变量不能出现在VAR语句中。
例如 例16-1
data temp;
input x1-x4;
cards;
40 2.0 5 20
10 1.5 5 30
120 3.0 13 50
250 4.5 18 0
120 3.5 9 50
10 1.5 12 50
40 1.0 19 40
270 4.0 13 60
280 3.5 11 60
170 3.0 9 60
180 3.5 14 40
130 2.0 30 50
220 1.5 17 20
160 1.5 35 60
220 2.5 14 30
140 2.0 20 20
220 2.0 14 10
40 1.0 10 0
20 1.0 12 60
120 2.0 20 0
;
proc princomp data=temp out=out1 outstat=stat1 prefix=z;
var x1-x4;
run;
proc print data=out1;
title 'output:out1';
run;
proc print data=stat1;
title 'output:stat1';
run;
12-因子分析
前面已讨论了多元线性回归分析、主成分分析等,它们的共同特点是讨论内容为可测量变量之间的相互关系,即所分析的这些变量是可以直接观察或测量得到的。但是,在医学研究中,很多情况下我们所要研究的变量是不能直接测量的。虽然这些潜在变量不能直接测量,但是它们是一种抽象的客观存在,因此一定与某些可测量变量有着某种程度的关联。
对于多指标数据中呈现出来的相关性,是否存在对这种相关性起支配作用的潜在变量?如果存在,如何找出这些潜在因素?这些潜在因素是怎样对原始指标起支配作用的?这些问题都可以通过因子分析来解决。
因子分析是一种旨在寻找隐藏在多变量数据中,无法直接观察到却影响或支配可测变量的潜在因子,并估计潜在因子对可测变量的影响程度,以及潜在因子之间的相关性的一种多元统计分析方法。其基本思想是从分析多变量数据的相关关系入手,找到支配这种相关关系的少数几个相关独立的潜在因子,并通过建立起这些潜在因子与原变量之间的数量关系来预测潜在因子的状态,帮助发现隐藏在原变量之间的某种客观规律性。因子分析和主成分分析都能够起到清理多个原始变量内在结构关系的作用,但主成分分析重在综合原始变量的信息,而因子分析重在解释原始变量间的关系,是比主成分分析更深入的一种多元统计方法
因子分析法就是寻找潜在因子的模型分析方法,它是在主成分的基础上构筑若干意义较为明确的潜在因子,以它们为框架分解原变量,以此考察原变量间的联系与区别。因子分析就是从大量的数据中"由表及里”、“去粗取精”,寻找影响或支配变量的多变量统计方法。可以说,因子分析是主成分分析的推广,也是一种把多个变量化为少数几个综合变量的多变量分析方法,其目的是用有限个不可观测的隐变量来解释原始变量之间的相关关系。
因子分析主要用于:(1) 减少分析变量个数。(2) 通过对变量间相关关系的探测,对原始变量进行分类,即将相关性高的变量分为一组,用共同的潜在因子代替该组变量。
因子分析法是从研究变量内部相关的依赖关系出发,把一些具有错综复杂关系的变量归结为少数几个综合因子的一种多变量统计分析方法。它的基本思想是对观测变量进行分类,将相关性较高,即联系比较紧密的分在同一类中,而不同类变量之间的相关性则较低,那么每一类变量实际上就代表了一个基本结构,即公共因子。对于所研究的问题,就是试图用最少个数的不可测的所谓公共因子的线性函数与特殊因子之和来描述原来观测的每一分量。
因子分析的核心问题有两个:一是如何构造因子变量;二是如何对因子变量进行命名解释。因此,因子分析的基本步骤和解决思路就是围绕这两个核心问题展开的。 (1) 因子分析常常有以下4 个基本步骤。
- 确认待分析的原变量是否适合作因子分析。
- 构造因子变量。
- 利用旋转方法使因子变量更具有可解释性。
- 计算因子变量得分。 (2) 因子分析的计算过程如下。
- 将原始数据标准化,以消除变量间在数量级和量纲上的不同。
- 求标准化数据的相关矩阵。
- 求相关矩阵的特征值和特征向量。
- 计算方差贡献率与累积方差贡献率。
- 确定因子。
- 因子旋转
- 用原指标的线性组合来求各因子得分
- 综合得分 (3) 得分排序:利用综合得分可以得到得分名次。
在采用多元统计分析技术进行数据处理、建立宏观或微观系统模型时,需要研究以下几个方面 的问题。
- 简化系统结构,探讨系统内核。
- 构造预测模型,进行预报控制。
- 进行数值分类,构造分类模式。

在 SAS系统中,可利用FACTOR过程对数据进行主成分分析。 FACTOR过程的语法格式如下。
PROC FACTOR DATA= N= OUT= OUTSTAT= METHOD= ROTATE= MAXITER= RECORDER HEY [选项];
VAR 变量/[选项];
PARTIAL 变量;
RUN;
各语句选项说明如下。
- DATA语句指定要分析的数据集名及一些选项,它可以是原SAS数据集,也可以是corr、cov、ucorr、ucov 等矩阵。
- N 用来确定潜在因子个数,该选择项缺省时,系统会自动根据"特征值大于1” 的原则确定潜在因子个数。
- OUT选择项用来保存原变量和因子得分变量,变量名为factor1, factor2, …。只有使用了 N 选择项,OUT选择项才能起作用。
- OUTSTAT选择项指定输出结果的SAS数据集名,该数据集保存的是每一个指标的均值、标准差、样本数、相关系数矩阵或方差协方差矩阵、特征值和特征向量、事前共性方差、事后共性方差、未旋转因子载荷、旋转线性变换、旋转后的因子载荷以及因子得分系数等。
- METHOD选择项用来确定因子分析的方法,可选用的有主成分分析法prin、最大似然分析法 ml、主因子分析法prinit等,缺省是prin。
- ROTATE选择项用来指定因子旋转的方法,可选用的有最大方差旋转法varimax、正交最大方差旋转法orthomax、相等最大方差旋转法equamax、比例最大方差旋转法promax等,缺省是none,不旋转。
- MAXITER选择项给出最大迭代次数,缺省是30。
- RECORDER指令系统将指标变量按每一个潜在因子载荷的绝对值从大到小重新排序。
- HEY表示将大于1 的共性方差的值设定为l。
- VAR语句用于列出要分析的原始变量。如果该语句缺省,系统则分析其他语句中未涉及的所有指标变量。
- PARTIAL语句用于列出混杂变量,指定系统使用偏相关系数或偏方差、协方差来计算主成分。 例如PARTIAL X ,它表示偏相关系数或偏方差、协方差是以变量X 为混杂变量的,即所有的相关系数都表示的是在X 不变的情况下,两个变量之间的关联程度。但是,该语句列出的变量不能出现在VAR语句中。
- 另外,有时也使用freq、weight, by等语句。
有的潜在因子是没有实际专业意义的。当因子分析从多个关系复杂的指标中找出主要的潜在因子后,对那些没有实际专业意义或不重要的潜在因子,在最后分析时应当舍去。
例如 例17-2
data temp (type=corr);
infile cards missover; input _name_ $3. x1-x12; _type_='Corr';
if _n_=1 then _type_='N'; else _type_='Corr';
cards;
df 40 40 40 40 40 40 40 40 40 40 40 40
x1 1.000 . . . . . . . . . . .
X2 0.6904 1.000 . . . . . . . . . .
X3 0.4115 0.4511 1.000 . . . . . . . . .
X4 0.4580 0.7068 0.4018 1.000 . . . . . . . .
X5 0.5535 0.6620 0.4122 0.7119 1.000 . . . . . . .
X6 0.3923 0.6317 0.4520 0.4583 0.5299 1.000 . . . . . .
X7 0.1415 0.3009 0.2025 0.2665 0.2480 0.1590 1.000 . . . . .
X8 0.0077 0.0344 0.1855 0.1065 0.0003 0.1100 0.3595 1.000 . . . .
X9 0.2385 0.3523 0.3646 0.3644 0.3388 0.3982 0.5004 0.3314 1.000 . . .
x10 0.0333 0.1726 0.1311 0.1757 0.1998 0.0342 0.5758 0.1420 0.2808 1.000 . .
x11 0.0898 0.3878 0.2041 0.3191 0.3186 0.2914 0.2537 0.2025 0.3971 0.1468 1.000 .
x12 0.2215 0.2427 0.4124 0.2169 0.1459 0.0985 0.4222 0.2156 0.5016 0.2286 0.0776 1.000
;
run;
proc factor data=temp rotate=varimax reorder;
var x1-x12;
run;
13-聚类分析
聚类分析是将样本个体或指标变量按其具有的特性进行分类的一种统计分析方法。我们所研究的样品或指标(变量)之间存在着程度不同的相似性(亲疏关系),于是可根据一批样品的多个观测指标,具体找出一些能够度量样品或指标之间相似程度的统计量,以这些统计量为划分类型的依据,把一些相似程度较大的样品(或指标)聚合为一类,把另外一些彼此之间相似程度较大的样品(或指标)又聚合为另一类,关系密切的聚合到一个小的分类单位,关系疏远的聚合到一个大的分类单位,直到把所有的样品(或指标)聚合完毕,这就是分类的基本思想。由此得知,聚类分析的任务有两个,一是寻找合理的度量事物相似性的统计量,二是寻找合理的分类方法。
在聚类分析中,通常根据分类对象的不同,分为Q型聚类分析和R型聚类分析两大类。Q 型聚类分析是对样本进行分类处理,又称为样本聚类分析;R型聚类分析是对指标进行分类处理,称为指标聚类分析。对样品进行聚类的目的是将分类不明确的样品按性质相似程度分为若干组,从而发现同类样品的共性和不同样品间的差异。对指标进行聚类的目的是将分类不明确的指标按性质相似程度分成若干组,从而在尽量不损失信息的条件下,用一组少量的指标来代替原来的多个指标。
R型聚类分析的主要作用是:①不但可以了解个别变量之间的关系的亲疏程度,而且可以了解各个指标组合之间的亲疏程度。②根据变量的分类结果以及它们之间的关系,可以选择主要变量进行回归分析或Q型聚类分析。
Q型聚类分析的作用是:①可以综合利用多个变量的信息对样本进行分类。②分类结果是直观的,聚类谱系图可以非常清楚地表现其数值分类结果,聚类分析所得到的结果比传统分类方法更细致、全面、合理。
无论是R型聚类还是Q型聚类,关键是如何定义相似性,即如何把相似性数量化。聚类的第一步需要给出两个指标或两个样品间相似性度量的统计量。
聚类分析中用来衡量样本个体之间属性相似程度的统计量和用来衡量指标变量之间属性相似程度的统计量是不同的,前者用的统计量是距离系数,后者用的统计量是相似系数。距离系数的定义有很多,如欧式距离、极端距离、绝对距离等。相似系数的定义也很多,如相关系数、列联系数等。
聚类分析的方法很多,常用的有系统聚类法和逐步聚类法。系统聚类法适用于小样本的样本聚类或指标聚类,逐步聚类法适用于大样本的样本聚类。对于小样本的样本聚类,如果采用逐步聚类法,聚类结果将与样本的顺序有关。
SAS系统中用于聚类分析的过程步有VARCLUS、CLUSTER和FASTCLUS。其中,VARCLUS过程步使用的是系统聚类法,用于指标聚类;CLUSTER过程步使用的也是系统聚类法,用于小样本的样本聚类;FASTCLUS过程步使用的是逐步聚类法,用于大样本的样品聚类。
13.1 PROC VARCLUS
在 SAS系统中,可利用VARCLUS过程步进行指标聚类。 VARCLUS过程的语法格式如下。
PROC VARCLUS DATA= OUTTREE= PROPORTION= MAXEIGEN= MAXC= MINC= [选项];
VAR变量/[选项];
RUN;
PROC TREE DATA= HORIZONTAL= PAGE= SPACE= ;
ID _NAME_ ;
RUN;
各语句选项的说明如下。 第1个过程步用于聚类指标变量,其中,DATA语句指定要分析的数据集名及一些选项,它可以是原SAS数据集,也可以是corr、cov、ucorr、ucov等矩阵。
- OUTTREE选择项用来保存用于绘制树状图的聚类信息。
- PROPORTION选择项用来指定所有类中指标变量的总变异至少应被类成分解释的比例。等号后面可以给出介于0和1之间的小数,也可以给出介于1和100之间的整数。PROPORTION=75和PROPORTION=0.75是等价的,表示聚类的结果必须满足所有类中指标变量的变异至少有75%被类成分所解释,如果一个类的比例小于此值,就要将它继续分解为两类。
- MAXEIGEN选择项用来指定所有类中第2特征值的最大允许值,超过此值就要分割为两类。
- MAXC选择项用来指定允许的最大类别数。
- MINC选择项用来指定允许的最小类别数。 第2个过程步用第1个过程步得到的结果绘制树状图,其中,DATA语句使用的是VARCLUS过程步的输出数据集,即由OUTTREE输出的数据集。
- HORIZONTAL选择项表示指令树状图的枝干绘制成水平的。
- PAGE选择项指定树状图所需的页数。
- SPACE选择项指定指标变量之间的间距(行数或列数)。
- ID语句给出的变量名用来作为树干刻度的标记,这个变量名是系统定义的,•由指标变量名构 成。
例如 例18-1
data temp;
input x1-x8;
cards;
7.78 48.44 8 20.51 22.12 15.73 1.15 16.61
10.85 44.68 7.32 14.51 17.13 12.08 1.26 11.57
9.09 28.12 7.4 9.62 17.26 11.12 2.49 12.65
8.35 23.53 7.51 8.62 17.42 10 1.04 11.21
9.25 23.75 6.61 9.19 17.77 10.48 1.72 10.51
7.9 39.77 8.49 12.94 19.27 11.05 2.04 13.29
8.19 30.5 4.72 9.78 16.28 7.6 2.52 10.32
7.73 29.2 5.42 9.43 19.29 8.49 2.52 10
8.28 64.34 8 22.22 20.06 15.52 0.72 22.89
7.21 45.79 7.66 10.36 16.56 12.86 2.25 11.69
7.68 50.37 11.35 13.3 19.25 14.59 2.75 14.87
8.14 37.75 9.61 8.49 13.15 9.76 1.28 11.28
10.6 52.41 7.7 9.98 12.53 11.7 2.31 14.69
6.25 35.02 4.72 6.28 10.03 7.15 1.93 10.39
8.82 33.7 7.59 10.98 18.82 14.73 1.78 10.1
9.42 27.93 8.2 8.14 16.17 9.42 1.55 9.76
8.67 36.05 7.31 7.75 16.67 11.68 2.38 12.88
6.77 38.69 6.01 8.82 14.79 11.44 1.74 13.29
12.47 76.39 5.52 11.24 14.52 22 5.46 25.5
7.27 52.65 3.84 9.16 13.03 15.26 1.98 14.57
13.45 55.85 5.5 7.45 9.55 9.52 2.21 16.3
7.18 40.91 7.32 8.94 17.6 12.75 1.14 14.8
7.67 35.71 8.04 8.31 15.13 7.76 1.41 13.25
9.98 37.69 7.01 8.94 16.15 11.08 0.83 11.67
7.94 39.65 20.97 20.82 22.52 12.41 1.75 7.9
9.41 28.2 5.77 10.8 16.36 11.56 1.53 12.17
9.16 27.98 9.01 9.32 15.99 9.1 1.82 11.35
10.06 28.64 10.52 10.05 16.18 8.39 1.96 10.81
8.7 28.12 7.21 10.53 19.45 13.3 1.66 11.96
6.93 29.85 4.54 9.49 16.62 10.65 1.88 13.61
;
proc varclus data=temp outtree=tree proportion=75;
var x1-x8;
run;
proc tree data=tree horizontal space=1;
id _name_;
run;
13.2 PROC CLUSTER
在SAS系统中,可利用CLUSTER过程步进行小样本聚类。 CLUSTER过程的语法格式如下。
PROC CLUSTER DATA= OUTTREE= METHOD= STANDARD NONORM RSQUARE [选项];
VAR 指标变量/[选项];
ID 样本序号变量;
RUN;
PROC TREE DATA= HORIZONTAL= PAGE= SPACE= ;
ID 样本序号变量;
RUN;
各语句选项的说明如下。
第1个过程步用于聚类样本中,其中,DATA语句指定要分析的数据集名及一些选项,它可以是原SAS数据集,也可以是corr、cov、ucorr、ucov等矩阵。
- OUTTREE选择项用来保存绘制树状图的聚类信息。
- METHOD选择项用于确定聚类的方法,选择的方法有single、complete、centroid、average、median、ward等,其中single表示最短距离法,complete表示最长距离法,centroid表示重心距离平均法,average表示平均距离平方法,median表示中间距离平均法,ward表示最小距离均差平方和法。
- STANDARD指令系统将原始数据标准化。
- NONORM表示类间距离不进行标准化。
- RSQUARE表述输出每一种聚类的复相关系数的平方和半偏复相关系数的平方,每一种聚类的复相关系数的平方等于总体变异被聚类成分所解释的比例,半偏复相关系数的平方等于由合并两个类引起的复相关系数平方的减少量。
- VAR语句给出用来聚类样本的指标变量。
- ID语句给出样本序号变量名。
第2个过程步用第1个过程步得到的结果绘制树状图,其中,DATA语句使用的是VARCLUS过程步的输出数据集,即由OUTTREE输出的数据集。
- HORIZONTAL选择项表示指令树状图的枝干绘制成水平的。
- PAGE选择项指定树状图所需的页数。
- SPACE选择项指定指标变量之间的间距(行数或列数)。
- ID语句给出的变量名也是用来作为树干刻度的标记,但这个变量名由样本序号构成。
- 另外,有时也使用freq、by等语句。
例如 例18-2
data temp;
input id x1-x16;
cards;
1 0.7728 18.8701 0.0000 0.7695 0.0000 44.9435 0.0000 16.5758 0.0000 0.0000 7.6919 2.1239 4.9656 3.0461 0.0000 0.0000
2 0.8642 19.9263 0.0000 0.8119 0.7419 45.9775 0.0000 13.6080 0.0000 0.0000 8.5596 1.5317 5.0254 1.3041 0.0000 0.0000
3 0.8243 21.0977 0.0000 0.4241 0.7293 45.1447 0.0000 15.6668 0.0000 0.0000 7.5724 1.8285 4.2709 1.4724 0.0000 0.0000
4 0.9229 20.0757 0.0000 0.7015 0.7018 44.3025 0.0000 15.9571 0.0000 0.0000 7.8116 1.9555 4.1090 1.6377 0.0000 0.0000
5 0.8873 20.7261 0.0000 0.4812 0.8167 45.7282 0.0000 14.6814 0.0000 0.0000 7.9308 1.9205 4.2299 1.5044 0.0000 0.0000
6 0.6894 10.1021 0.8601 2.8247 0.0000 11.0901 2.2253 14.7233 1.2605 1.6238 29.8684 1.4462 16.0572 4.6744 1.5475 0.9376
7 0.6287 17.4562 0.0000 0.8787 0.0000 51.1227 0.0000 16.6821 0.0000 0.0000 6.7399 1.3021 3.6787 1.0890 0.0000 0.0000
8 1.7146 21.0712 1.2745 6.9323 0.0000 11.9821 0.0000 14.2464 0.8387 1.1903 22.3226 1.0350 11.1513 3.2862 1.0540 0.6633
9 0.8440 20.7948 0.0000 0.5289 0.7024 42.4289 0.0000 17.1255 0.0000 0.0000 8.5508 1.9223 4.6346 1.3074 0.0000 0.0000
10 0.9797 23.4313 0.0000 0.4778 0.7890 43.9119 0.0000 14.5129 0.0000 0.0000 7.4513 1.7509 4.0373 1.4142 0.0000 0.0000
11 0.9811 23.5269 0.0000 0.4989 0.8375 42.3814 0.0000 14.8207 0.0000 0.0000 7.5800 1.8551 3.9729 1.3863 0.0000 0.0000
12 1.0560 17.4586 1.0481 1.1591 0.6113 15.8986 2.1618 13.1660 1.1251 1.2887 23.9812 1.5252 11.7911 3.5647 1.2011 0.7989
13 0.3342 10.9218 0.0000 0.9379 0.0000 30.5689 0.0000 16.1205 0.8614 0.9350 20.0491 2.4606 10.9263 2.9423 0.9680 0.5866
14 1.3816 15.9731 1.0270 1.2106 0.5663 20.0942 2.1881 11.7304 1.1318 1.3370 23.1882 1.3790 11.7141 3.5635 1.1838 0.7657
15 1.3435 23.1294 1.2489 0.8939 0.0000 12.3388 2.0595 12.1598 1.1842 1.3267 23.9904 1.1520 11.9333 3.6034 1.1375 0.7110
16 2.3861 19.7456 0.0000 0.9093 0.3389 68.8572 0.0000 4.9522 0.0000 0.0000 0.0000 1.6429 0.0000 0.0000 0.0000 0.0000
17 1.6180 23.5786 0.0000 2.6597 0.0000 12.3110 0.0000 14.0923 0.8883 1.2167 23.3105 1.3039 11.7462 3.4875 1.1042 0.6779
18 1.0469 23.6999 0.0000 0.7698 0.7172 49.0165 0.0000 12.1561 0.0000 0.0000 5.5289 2.2450 2.8850 0.9707 0.0000 0.0000
19 0.7539 13.0284 0.0000 2.2978 0.8085 30.6336 0.0000 10.4001 0.8754 1.4161 20.6589 2.4703 10.2990 2.9556 0.9522 0.6328
20 1.3813 23.0962 0.0000 1.7688 0.0000 21.8800 0.0000 14.6781 0.7285 0.9902 18 5709 1.5253 9.5387 2.8917 1.0169
21 0.4162 8.6635 0.0000 1.4322 0.6001 28.0838 0.0000 13.7243 1.0979 1.5293 22.6316 2.6314 12.3223 3.4616 1.1200 0.7169
22 2.0717 21.1906 0.0000 1.1577 0.6255 66.8966 0.0000 5.6805 0.0000 0.0000 0.0000 1.6632 0.0000 0.0000 0.0000 0.0000
23 1.0133 17.2585 0.0000 1.1623 0.6673 19.7117 0.0000 14.8122 1.0789 1.3638 23.0015 1.7719 11.4394 3.3958 1.0658 0.6366
24 0.3346 7.0428 0.0000 1.1386 0.5445 27.0624 0.0000 14.2519 1.1650 1.4980 23.8449 2.5176 13.2688 3.6558 1.1239 0.7382
;
proc cluster data=temp method=average outtree=tree standard nonorm rsquare ccc;
var x1-x16;
id id;
run;
proc tree data=tree horizontal space=1 page=1;
id id;
run;
1.3 PROC FASTCLUS
用于大样本样品聚类的FASTCLUS过程步使用的是逐步聚类法,其聚类原则是使得类间距离最小。 和 CLUSTER过程步相比,FASTCLUS过程步的缺点是:
- 没有将原始数据标准化的功能;
- 不能自动确定类别数;
- 需要确定初始凝聚点;
- 不能输出作树状图的聚类信息。
因此,在使用FASTCLUS过程步前,①要用STANDARD过程步将原始数据标准化,即将原始数据化为均值为0、标准差为1的标准化数据。②要根据经验确定类别数。③要根据经验选取凝聚点,或者在确定类别数的基础上指令系统自动选取初始凝聚点。
FASTCLUS过程步的优点是能快速地对大样本进行样本聚类,且聚类后输出类内指标的均值,用于比较类间的差异,找出每一类的特性。 FASTCLUS过程的语法格式如下。
PROC STANDARD DATA= OUT= MEAN=0 STD=1;
VAR 指标变量;
RUN;
PROC FASTCLUS DATA= MAXC= RADIUS= MAXITER= LIST DISTANCE OUT= OUTSTAT= VARDEF= [选项];
VAR 指标变量;
RUN;
各语句选项的说明如下。 第 1个过程步用于将数据标准化,标准化的数据存在新数据集中。
- OUT选择项给出含有标准化数据的新数据集名。
- MEAN选择项给出标准化数据的均值,一般取MEAN=0。
- STD选择项给出标准化数据的标准差,一般取STD=1。
- VAR语句给出需要标准化的变量。 第2 个过程用来聚类样本,使用的数据是上面过程步得到的标准化变量。
- DATA语句给出上面过程步得到的含有标准化变量的新数据集。
- MAXC选择项用来指定允许的最大类别数。
- RADIUS选择项给出确定新凝聚点的准则r,即只有当一个点在以原凝聚点为中心,以r为半径的圆外时,才能被选为新的凝聚点。如果这样的点不存在,聚类则停止。
- MAXITER选择项给出递推运算的次数。
- LIST表明列出每一个样品的归类结果。
- DISTANCE表明输出类内样品均值间的距离。
1.4 PROC ACECLUS
某些场合下用CLUSTER或 FASTCLUS过程进行样品聚类效果不佳,这可能是由于资料不满足经典聚分析方法所要求的条件所致,为此,SAS提供了一个专门用于对需作样品聚类分析的资料进行预处理的过程,即ACECLUS过程,它可以对数据进行线性转换,使转换后的数据满足经典聚类分析方法的要求。
例如 例18-4
proc aceclus out=aaa p=0.02;
proc cluster data=aaa method=average outtree=tree standard nonorm rsquare ccc;
var x1-x16;
id id;
run;
proc tree data=tree horizontal space=1 page=1;
id id;
run;
14-判别分析
判别分析的任务是根据已掌握的一批分类明确的样品建立判别函数,使产生错判的事例最少,进而对给定的一个新样品,判断它来自哪个总体。判别分析是对样本个体进行分类的另一种统计分析方法,它和聚类分析一样,都可以将样本个体按其具有的特性进行分类。但是聚类分析和判别分析有很大的区别,判别分析是根据一批分类明确的样本在若干指标上的观察值,建立一个判别函数和判别准则,然后以此准则对新的样本进行分类。
由此可知,这两种分类方法有着本质的不同:①聚类分析可以对样本进行分类,也可以对指标进行分类;而判别分析只能对样本进行分类。②聚类分析事先不知道事物的类别,也不知道分几类;而判别分析必须事先知道事物的类别,也知道分几类。③聚类分析不需要分类的历史资料,而是直接对样本进行分类;判别分析需要分类历史资料去建立判别函数,然后才能对样本进行分类。
判别分析的基本思想是根据一批分类明确的样本在若干指标上的观察值,建立一个关于指标的判别函数和判别准则,然后根据这个判别函数和判别准则对新的样本进行分类,并且根据回代判别的准确率评估它的实用性。
判别函数是一个关于指标变量的函数。每一个样本在指标变量上的观察值代入判别函数后可以得到一确定的函数值,将所有样本按其函数值的大小和事先规定的判别原则分到不同的组里,并使得分组结果与原样本归属最吻合,这就是判别分析方法的基本过程。进行判别分析的目的是根据样本建立判别函数和判别准则,用以对新的样本进行归类。不同判别分析方法的区别在于,其建立判别函数的方法和判别准则的规定是不同的。
判别分析的方法中较常使用的有Bayes判别分析法和Fisher判别分析法。Fisher判别分析法是以距离为判别准则来分类,即样本与哪个类的距离最短就分到哪一类;而Bayes判别分析法则是以概率为判别准则来分类,即样本属于哪一类的概率最大就分到哪一类。前者仅适用于两类判别,后者则适用于多类判别。
对判别分析结果的优劣评价尚无系统的检验理论,而只能通过错判率和事后概率错误率的估计来评估判别分类的有效性。
- FISHER判别函数和判别准则可以看出,如果把一个样本的k个观察值看做k维空间中的一个点,那么,FISHER判别分析法的判别准则是使得类间点的距离最大,而类内点的距离最小,也就是说,它是以距离为判别准则的。FISHER判别分析法只能解决两类的判别分析。
- BAYES判别分析法是以概率为判别准则,使得每一类中的每一个样本都以最大概率进入该类。BAYES判别是一种概率型的判别分析,在分析过程开始时需要获得各个类别的分布密度函数,同时也需要知道样本点属于各个类别的先验概率,以建立一个合适的判别规则;而分析过程结束时则计算每个样本点归属于某个类别的最大概率或最小错判损失,以确定各个样本点的预测类别归属。
AYES判别分析法在理论和处理方法上都比FISHER判别分析法更加完善和先进,它不仅能解决多类判别分析,而且分析时考虑了数据的分布状态,使得判别分析的效能得到了较大的提高。SAS软件的判别分析过程是以BAYES判别分析法为理论基础的。判别分析的结果对应着分析的不同步骤过程,也就包括了分类规则和分类结果两个部分。在分类规则中应该包括典型判别函数、衡量预测变量与判别函数之间关系的结构矩阵,以及Fisher线性分类函数。
一个判别函数判别样本归类的功能强弱很大程度上取决于指标的选取。判别函数中特异性强的指标越多,则判别函数的判别功能也就越强。相反,不重要的指标越多,判别函数就越不稳定,其判别效果非但得不到改善,甚至会适得其反。因此,要建立一个有效的判别函数,指标的选取很重要,过多过少都不一定合适。一方面要根据专业知识和经验来筛选指标,另一方面要借助统计分析方法检验指标的性能。
在一个判别函数中,每一个指标变量对判别函数的判别能力都有所贡献,贡献的大小可以用一元方差分析和多元方差分析来检验。一元方差分析用于检验每一个指标是否对判别函数的判别能力有显著性意义,统计检验的无效假设是:单一指标对判别函数的作用不显著。多元方差分析用于检验所有的指标是否联合对判别函数的判别能力有显著性意义,统计检验的无效假设是:所有的指标对判别函数的联合作用不显著。
对于BAYES参数分析法的判别准则效能的评估,常用的是两个错误率估计指标,一个为错判率估计,另一个为事后概率错误率估计。对于一个估计的BAYES判别准则,错判率和事后概率错误率越小,判别准则就越准确可靠。当被判别的新样本与样本独立时,这两种错误率估计是非偏的。但是,当新样本数很小时,可能会产生很大的变异,这时,事后概率错误率估计值有时会小于0。因此,为了得到一个有效的错误率估计,被判别的数据中的样本数不应当太小,且类内样本数比例应当接近类内事前概率。
总之,评估一个判别函数的判别效能,一般会涉及以下几个方面。
- 原数据的分类要可靠准确。
- 指标变量对判别函数的作用要显著。
- 错判率和事后概率的错误率要适当小。
在SAS系统里,用来进行判别分析的过程步有DISCRIM、STEPDISC和CANDISC。较常用的过程步是DISCRIM和STEPDISC,它们的区别是后者仅用来筛选指标变量,且仅适用于类内为多元正态分布,具有相同方差协方差矩阵的数据。前者可以筛选指标,适用于各种数据,且类内为多元正态分布时,不要求具有相同的方差协方差矩阵。一般来说,当指标变量较多时,可以将两者结合使用,即首先使用STEPDISC过程步筛选指标变量,然后用DISCRIM过程步为筛选出来的指标变量建立判别函数。CANDISC过程步用来进行正交判别分析,正交判别分析是一种减少维数(指标个数)的判别分析,作用类似于主成分分析。
14.1 PROC DISCRIM
DISCRIM过程的语法格式如下。
PROC DISCRIM DATA= OUTSTAT= OUT= SIMPLE ANOVA MANOVA POOL=YES/NO /TEST LISTERR POSTERR;
CLASS 分类变量;
VAR 指标变量;
PRIOR PROP '数值 1' =p₁,…,'数值 k'=pₖ ;
RUN;
PROC DISCRIM DATA= TESTDATA= TESTLIST POSTERR;
CLASS 分类变量;
VAR 指标变量;
RUN;
各语句选项的说明如下。 第1个过程步用于建立判别函数,其中,DATA语句指定要分析的数据集名及一些选项,它可以是原SAS数据集,也可以是corr、cov、ucorr、ucov等矩阵。
- OUTSTAT选择项指定输出结果的SAS数据集名,用来保存判别分析输出的结果,如均值、标准差、判别函数的系数等,用于下一步判别新的样本。
- SIMPLE选择项指令系统输出每一个指标变量的基本统计量和每一类内的基本统计量。
- ANOVA选择项指令系统输出每一个指标变量的一元方差分析结果,用于检验每一个指标变量在每一类上的均值是否都相等。如果拒绝无效假设,则说明该指标变量对判别函数的判别能力有显著性意义。
- MANOVA选择项指令系统输出所有指标变量的多元方差分析结果,用于检验所有指标变量在每一类上的均值是否都相等。如果拒绝无效假设,则说明所有指标变量的联合作用对判别函数的判别能力有显著性意义。
- POOL选择项用来确定方差协方差矩阵V 的形式:POOL=YES指令系统选择合并的方差协方差矩阵,这时输出的判别函数是一次线性函数;POOL=NO选择类内的方差协方差矩阵,这时输出的判别函数是二次线性函数;POOL=TEST用来检验类间方差的一致性,方法是Bartlett的修正似 然比检验法。对于正态分布的数据,Bartlett检验法是一个非偏检验,SAS系统设定的检验水平是 0.10,若要改变它,可以添加SLPOOL=选择项来确定。POOL=TEST不仅可以检验类间方差的一致性,而且可以根据检验结果自动确定在判别函数中使用哪一种方差协方差矩阵。因此一般情况下,选用POOL=TEST是最简单、最便捷的方法。
- LIST选择项指令系统输出每一个样本的回代结果,包括每一个样本的事后概率以及根据BAYES判别准则重新分类的准确率和错误率。
- LISTERR选择项指令系统输出错判的样本的回代结果。LIST和 LISTERR这两个选项中只需要选用一个即可,当样本大时应选择后者。
- POSTERR选择项指令系统输出用所建立的判别函数来判别样本分类时所产生的事后概率错误率估计。
- CLASS语句用来指定分类变量,这个分类变量可以是数值型变量,也可以是字符型变量。
- VAR语句列出了用来建立判别函数的指标变量,它们必须是连续型数值变量。
- PRIOR语句用来确定每一个点属于每一类的事前概率,它有以下3 种写法。
- (1) PRIOR PROP:表明事前概率等于样本估计值。
- (2) PRIOR EQUAL:表示事前概率相等,即每一个点具有相等的事前概率进入每一类。
- (3) PRIOR ‘1’=0.4 ‘2 =0.6:表示CLASS语句中的分类变量仅取值1和 2 , 每一个点进入类’1’的事前概率等于0.4,进入类’2’的事前概率等于0.6。如果PRIOR语句缺省,系统则使用EQUAL作为事前概率。第2个过程步以第1个过程步得到的判别函数来判别新的样本,其中,DATA语句给出第1个DISCRIM过程步的OUTSTAT后面列出的输出数据集名。
- TESTDATA给出含有新样本的数据集名,其中变量名必须与第1个过程步中使用的变量名一致。
- TESTLIST指令系统输出被检验的新数据集中每一个新样本的分类结果。
- POSTERR指令系统输出用第1个过程步建立的判别函数来判别新样本时所产生的事后概率错误率估计。
- CLASS语句列出的变量必须与第1个过程步的CLASS语句列出的变量一样。
- VAR语句列出用来建立判别函数的指标变量。
- 另外,有时也使用freq、weight、by等语句。
14.2 PROC STEPDISC
SAS系统中的STEPDISC过程用于完成逐步判别分析。STEPDISC过程步定义了 3 种筛选指标 变量进入判别函数的方法,它们是向前选择法、向后选择法和逐步选择法。 STEPDISC过程的语法格式如下。
PROC STEPDISC DATA= METHOD= FORWARD|BACKWARD|STEPWISE SLE= SLS= [选项];
CLASS 变量;
VAR 变量/[选项];
RUN;
各语句选项的说明如下。
- DATA语句指定要分析的数据集名及一些选项,可以是原SAS数据集,也可以是corr、cov、 ucorr、ucov等矩阵。
- METHOD=语句用来确定逐步选择指标变量的方法,缺省值是stepwise。
- Sle和sls分别给出进入水平和停留水平,缺省值均为0.15。
- CLASS语句用来指定分类变量,这个分类变量可以是数值型变量,也可以是字符型变量。
- VAR语句列出用来建立判别函数的指标变量,它们必须是连续型数值变量。 另外,有时也可使用freq、weight>by等语句。
14.3 PROC CANDISC
典型判别分析是典型相关的特殊情况,即一组变数为连续变数,另一组变数为名义变数的情况下所使用的判别分析法。使用PROC CANDISC分析,可找出连续变数间各种线性组合所求之新变数,称之为典型变数,使其尽可能判别区分名义变数之不同类别。 在 SAS系统中,可使用CANDISC过程完成典型判别分析。该过程用于计算马氏平方距离,并做单变量与多变量的方差分析,还可产生典型相关系数和典型变量得分的输出数据集。 CANDISC过程的语法格式如下。
PROC CANDISC DATA= OUT= ANOVA MANOVA DISTANCE [选项];
CLASS 变量;
VAR 变量/[选项];
RUN;
各语句选项的说明如下。
- DATA语句指定要分析的数据集名及一些选项,它可以是原SAS数据集,也可以是corr、cov、ucorr、ucov等矩阵。
- OUT选择项用来保存原始变量和典型变量,存储新的数据集。
- ANOVA选择项指令系统输出每一个指标变量的一元方差分析结果,用于检验每一个指标变量在每一类上的均值是否都相等。如果拒绝无效假设,则说明该指标变量对判别函数的判别能力有显著性意义。
- MANOVA选择项指令系统输出所有指标变量的多元方差分析结果,用于检验所有指标变量在每一类上的均值是否都相等。如果拒绝无效假设,则说明所有指标变量的联合作用对判别函数的判别能力有显著性意义。
- DISTANCE选择项要求计算类间的平方马氏距离并输出计算结果。
- CLASS语句用来指定分类变量,这个分类变量可以是数值型变量,也可以是字符型变量。
- VAR语句列出用来建立判别函数的指标变量,它们必须是连续型数值变量。
- 另外,有时也可使用freq、weight、by等语句。
15-典型相关分析(略)
16-诊断试验的ROC分析(略)
17-一致性检验Kappa(略)
18-概率抽样方法(略)
19-样本量估计(略)
20-统计图
统计图的种类很多,应根据资料的类型和目的选用合适的统计图。定性资料可选用的统计图有直条图、圆图、统计地图等;定量资料可选用的统计图有直方图(或多边图)、普通线图、半对数线图、散点图等。不同的统计图,以不同的方式或姿态来形象化地表达资料。因此,掌握各种统计图的特征,有助于正确选用统计图。
制作统计图的一般原则如下。 (1)根据资料性质和分析目的正确选用适当的统计图。 例如,分析比较独立的、不连续的、无 数量关系的多个组或多个类别的统计量宜选用直条图,分析某指标随时间或其他连续变量变化而变化的趋势宜选用线图,描述某变量的频数宜选用直方图,描述或比较不同事物内部构成时宜选用圆图或百分条图等。 (2)统计图必须有标题、概括统计图资料的时间、地点和主要内容。统计图的标题在图的下方。 (3)统计图一般有横轴和纵轴,并分别用横标目和纵标目说明横轴和纵轴代表的指标和单位。一般将两轴的相交点即原点处定为0。 (4)统计图用不同的线条和颜色表达不同事物和对象的统计量,需要附图加以说明。
20.1 直条图
直条图用来表示各相互独立的统计指标的数量大小。通常,纵轴表达数量,横轴表达分组标志。用绝对数或相对数均可表达数量,其数量大小用图中各长条的高度来反映。直条图用相同宽度的直条长短表示相互独立的某统计指标值的大小。直条图按照是横放还是竖放分卧式和立式两种,按对象的分组是单层次和两层次分单式和复式两种。
直条图的直条尺度必须从0开始,各直条的宽度相等,间隔一般与直条等宽或为其一半。直条排列的顺序可按指标值大小排列,也可按分组的自然顺序排列。
在 SAS系统中,可采用GCHART过程步绘制直条图。 GCHART过程步的语法格式如下。
PROC GCHART [ DATA=<数据集名> [选项] ] ;
HBAR <变量名列> / [选项] ;
VBAR <变量名列> / [选项];
BLOCK <变量名列> / [选项];
PIE <变量名列> / [选项];
STAR <变量名列> / [选项];
AXISn [选项];
BY <变量名列>;
RUN;
各语句选项的说明如下。
- HBAR选择项指令系统绘制立式直条图。
- VBAR选择项指令系统绘制水平直条图。
- BLOCK选择项指令系统绘制三维直方图。
- PIE选择项指令系统绘制饼图。
- STAR选择项指令系统绘制星状图。
- AXISn选择项控制坐标轴的形状和颜色。 BY选择项指令系统按该变量取值分层绘制,要求数据集已按该变量排序。
- MISSING指定绘图时要将变量的缺失值也包括在内。
- TYPE=做图类型关键字,指定要做图的类型,即图中条块代表的含义,默认值是频数(FREQ); 如果指定了选择项SUMVAR,则默认值为总和(SUM)。可选的关键字如下:
- FREQ要求按指定变量的频数做图。
- PERCENT要求按在横轴刻度表示范围内出现的频数占总数的百分比做图。
- CFREQ,按累计频数做图。
- CPERCENT,按累计百分比做图。
- SUM只能与SUMVAR选项同时使用,要求图中的每一条代表:变量在横轴表示的取值范围内时,SUMVAR指定变量的总和。
- MEAN只能与SUMVAR选项同时使用,要求图中的每一条代表:变量在横轴表示的取值范围 内时,SUMVAR指定变量的均数。
- SUMVAR=求和变量,指定使用TYPE=SUM或 MEAN时,用于求总和、均值的变量。
- LEVAL=n,如果绘图变量是连续变量,可以用该选项产生有N 个组段的图形。 GROUP=分组变量,要求产生以分组变量的值分组的并排图。
- SUBGROUP=亚组变量,要求每个图形内部再按亚组变量的值分块。
- CAXIS=颜色,指定坐标轴的颜色。
- CTEXT=颜色,指定坐标轴文本的颜色。
例如 例25-1
data temp;
input gender $ unit $ age @@;
cards;
M IN 27 M OUT 30 F IN 24
M IN 36 F IN 22 F OUT 32
F OUT 36 F IN 28 M IN 26
M OUT 40 F OUT 38 F IN 31
F OUT 21 F IN 27 M IN 34
M IN 29 M OUT 33 F OUT 35
M IN 24 F IN 23 M IN 37
F IN 27 F IN 34 M OUT 41
F OUT 30 M IN 26 F IN 29
F IN 30 F OUT 23 F IN 36
;
proc gchart data=temp;
hbar gender/group=unit type=sum sumvar=age;
run;
20.2 圆图
圆图用来表示事物内部的构成情况。必须用相对数,且各项之和为100% ,图中各扇形的面积表示数量的大小,将 360度圆心角看成100% ,把每一部分所占的百分数折算成圆心角的度数,根据圆心角的度数就可以画出代表各部分数量大小的扇形。百分条图是以矩形总长度作为100% ,将其分割成不同长度的段来表示各构成的比例。圆图和百分条图适合描述分类变量的各类别所占的构成比。
例如 例25-2
data temp;
input gender $ unit $ age @@;
cards;
M IN 27 M OUT 30 F IN 24
M IN 36 F IN 22 F OUT 32
F OUT 36 F IN 28 M IN 26
M OUT 40 F OUT 38 F IN 31
F OUT 21 F IN 27 M IN 34
M IN 29 M OUT 33 F OUT 35
M IN 24 F IN 23 M IN 37
F IN 27 F IN 34 M OUT 41
F OUT 30 M IN 26 F IN 29
F IN 30 F OUT 23 F IN 36
;
proc gchart data=temp;
pie unit gender;
run;
20.3 线图
线图也称折线图,是用线段的升降来表示数值的变化,适合于描述某统计量随另一连续性数值变量变化而变化的趋势。它分为普通线图和半对数线图两种。普通线图,资料中包含着两个计量指标,放在横轴上的计量指标通常是时间,放在纵轴上的计量指标通常是某种率。画图时,纵、横轴上的尺度一律用算术尺度。它适合于表达一个或者多个事物或现象随着时间的推移,数量的增减幅度。
在 SAS系统中,可采用GPLOT过程步绘制线图。 GPLOT过程的语法格式如下。
PROC GPLOT [ DATA=<数据集名> [选项] ] ;
PLOT <纵坐标变量*横坐标变量> / [选项] ;
PLOT2<纵坐标变量*横坐标变量> / [选项] ;
SYMBOLn [选项];
BY <变量名列>;
RUN;
各语句选项的说明如下。
- PLOT2选择项指令系统在原图基础上重叠绘制第2幅散点图。
- SYMBOLn选择项定义符号,添加趋势线,定义点和线的颜色。
- BY选择项指令系统按该变量取值分层绘制,要求数据集己按该变量排序。
- UNIFORM要求用BY语句分组打印的散点图的坐标刻度相同,以便于比较。.
- VTOH=数值,指定纵横坐标的比例。
- OVERLAY,同一语句做的图重叠在同一个坐标系中显示。
- HAXIS=数值,定义横坐标的刻度。
- VAXIS=数值,定义纵坐标的刻度。
- CAXIS=颜色,定义坐标轴的颜色。
- CTEXT=颜色,定义坐标轴文本的颜色。
- I=连线方式:JOIN用直线连接,SPLINE用光滑的曲线连接,NEEDLE向横坐标画垂线,RL添加回归直线。
- WIDTH=宽度,定义数据点和连线的宽度。
- COLOR=颜色,定义数据点和连线的颜色。
例如 例25-3
data temp;
input x y @@;
cards;
56 147 42 125 72 160 36 118 63 149 47 128
55 180 49 145 38 115 42 140 68 152 60 115
;
symbol v=dot I=rl ci=red cv=green;
proc gplot data=temp;
plot y*x;
run;
20.4 半对数线图
半对数线图是一种基本的统计图形,特别适宜作为不同指标变化速度的比较,它与普通线图(习惯上简称线图)一样,均可通过线段的上升或下降来表示一个指标随另一指标(常为时间)变化而变化的情况。两者的区别在于普通线图的横、纵坐标均为算术尺度,在某两个不同的时间段上,如果终点相对于起点的“绝对改变量”相同,将在图形上表现为相同的增幅(或减幅),直观呈现的是数量变化的态势;半对数线图的横坐标仍为算术尺度(如时间),纵坐标指示的观察指标(常为研究的指标,如发病率、病死率等)则实施了对数转换—— 即对数尺度,在某两个不同的时间段上,如果终点相对于起点的“相对改变量”相同,将在半对数线图上表现为相同的增幅(或减幅),所以半对数线图适用于呈现事物发展变化的速度。两种图形从不同的角度反映被观察指标的变化情况,但两者的意义和适用场合区别甚大,使用时要根据具体情况正确选用。如果研究者一概应用普通线图来反映动态数据的变化情况,则可能导致无法正确呈现资料所蕴含的信息。
当研究两组或多组数据的变化情况时,普通线图用来说明研究指标的波动态势,半对数线图用来说明研究指标的变化速度。在 SAS系统中,也是采用GPLOT过程步绘制半对数线图。
例如 例25-4
data temp;
do time=1 to 15;
input drug@@;
lgdrug=log(drug);
output;end;
cards;
2 8 16 64 100 81 54 36 18 9 8 4 2
;
symbol v=dot I=join;
proc gplot data=temp;
plot lgdrug*time;
run;
20.5 箱线图
箱线图是由一组数据的5个特征值绘制而成的,它由一个箱子和两条线段组成。5个特征值依次是最大值、上四分位数、中位数、下四分位数和最小值。通过箱线图,可以反映出数据分布的特征。
箱线图一般有单批数据箱线图和多批数据箱线图两种。
在 SAS系统中,通过UNIVARAITE过程步就可以绘制箱线图。
例如 例25-5
data temp;
input beishu@@;
cards;
100 200 400 400 400 400 800 1600 1600 1600 3200
;
proc univariate plot; var beishu;
run;
例如 例25-6
data temp;
input type$ beishu@@;
cards;
A 100 A 200 A 400 A 400 A 400 A 400
A 800 A 1600 A 1600 A 1600 A 3200
B 100 B 100 B 100 B 200 B 200 B 200
B 200 B 400 B 400
;
proc format;
value $tt A='标准株' B='水生株';
proc boxplot; plot beishu*type; format type $tt.;
run;
20.6 散点图
散点图表示两种事物变量的相关性和趋势。医学上常用于观察两种生理指标之间的动态变化关系,或临床上两项检测结果之间的量变关系。资料中包含着两个计量指标,如果两变量之间有自变量与因变量之分,通常把自变量放在横轴上;把因变量放在纵轴上。将成对的数据(X,Y)在直角坐标系中用圆点表示出来,就称为散点图。它可以形象地反映出在专业上有一定联系的两个连续变量之间的变化趋势,可借助它帮助判断是否值得进行直线相关和回归分析,或拟合何种类型的曲线方程。
在 SAS系统中,可利用GPLOT过程绘制散点图。
例如 例25-7
data temp;
input x y @@;
cards;
1.21 3.90 1.30 4.50 1.39 4.20 1.42 4.83 1.47 4.16
1.56 4.93 1.68 4.32 1.72 4.99 1.98 4.70 2.10 5.20
;
proc gplot;
plot y*x;
run;
20.7 直方图
数值型数据表现为数字,在整理时通常进行数据分组。分组是根据统计研究的需要,将数据按照某种标准分成不同的组别。直方图是用矩形的宽度和高度来表示频数分布的图形。用横轴表示数据分组,纵轴表示频数或频率。
直方图是以直方面积描述各组频数的多少,面积的总和相当于各组频数之和,适合表示数值变量的频数分布。直方图的横轴尺度是数值变量值,纵轴是频数。须注意如各组组距不等时,要折合成等距后再绘图,即将频数除以组距得到单位组距的频数作为直方的高度,组距为直方的宽度。
在 SAS系统中,可通过CAPABILITY过程步绘制直方图。
例如 例25-8
data temp;
input height @@;
cards;
170.7 174.1 166.7 179.7 171.0 168.0 177.3 174.5
174.1 173.3 169.0 173.5 173.1 177.5 180.0 173.2
173.1 172.4 173.6 175.3 181.5 170.8 176.4 171.0
171.8 180.7 170.7 173.8 164.9 170.0 177.7 171.4
163.5 178.8 174.9 178.3 174.1 174.3 171.4 173.2
173.7 173.4 174.2 172.9 176.9 168.3 175.1 172.1
166.8 172.8 168.8 172.5 172.8 175.2 170.9 168.6
168.6 169.1 168.8 172.0 168.2 172.8 169.1 173.6
169.6 172.8 175.7 178.8 170.1 175.5 171.7 168.6
171.2 170.1 170.7 173.6 167.2 170.8 174.8 171.8
174.9 168.5 178.7 177.3 165.9 174.2 170.2 169.5
172.1 178.1 171.2 176.0 169.8 177.9 171.6 179.4
183.8 168.3 175.6 175.9 182.2
;
proc capability ;
histogram height / cfill=gray;
run;
20.8 统计地图
统计地图用来表示事物的数量在地域上的情况,如反映疾病的地区分布情况。统计地图用不同的颜色和花纹表示统计量的值在地理分布上的变化,适宜描述研究指标的地理分布。统计地图先绘制按行政区域或地理特征分区的地图,然后按各区域统计指标值分别标记不同的颜色或花纹,并加以图例说明不同颜色或花纹的意义。注意颜色或花纹的选择最好与统计量数值增减的趋势一致。
利用SAS的GMAP,可以在地图上制作二维或三维的统计图,直观地显示地区性的差异。
请注意,SAS最新版本的Maps库需要前往“SAS资源管理器”-“当前逻辑库”-“Maps”处查看。
例如 例25-9
data temp;
input id idnumber $ ill@@;
cards;
1 Anhui 1065
2 Zhejiang 3114
3 Jiangxi 1378
4 Jiangsu 2209
5 Jilin 40245
6 Qinghai 95
7 Fujian 3035
8 Heilongjiang 2972
9 Henan 2921
10 Hebei 1998
11 Hunan 1386
12 Hubei 68398
13 Xinjiang 1008
14 Xizang 1
15 Gansu 681
16 Guangxi 1590
18 Guizhou 179
19 Liaoning 1652
20 NeiMongol 1752
21 Ningxia 122
22 Beijing 2289
23 Shanghai 59605
24 Shanxi 420
25 Shandong 2729
26 Shaanxi 3277
28 Tianjin 1804
29 Yunnan 2119
30 Guangdong 7103
31 Hainan 288
32 Sichuan 2064
33 Chongqing 699
34 HongKong 330880
35 Macau 82
36 Taiwan 202418
;
proc sort;
by idnumber; run;
proc sort data=maps.china2
out=maps;
by idname2;
data both;
merge maps temp;
run;
proc gmap data=both;
id _map_geometry_;
block ill
/midpoints=0 to 331000 by 5000;
run;
参考资料
SAS统计分析与应用从入门到精通_第2版(访问密码:1751)






暂无评论内容