
一、这项工作的意义及一些基本概念

-
Reads数

-
测序深度
- 测序深度(Sequencing Depth)是指:测序得到的碱基总量(bp)与基因组(转录组或测序目标区域大小)的比值,是评价测序量的指标之一。 工欲善其事,必先利其器 先来了解一下测序深度
-
Kilobase:千碱基

二、三种方法原理
2.1 RPKM (Reads Per Kilobase Million)
適用於单端测序文库
- 第一步先將测序深度標准化,计算方法很简单,【样品该基因的数该样品所有基因数的和】先分別计算出每个样本的总reads数(这里以10为单位),然后將表中数据分別除以总reads数即可,这样就得到了reads per million.【$\frac{样品该基因的reads数}{该样品所有基因reads数的和}$】
- 第二步即是基因长度的標准化了。將表2的read per million直接除以基因长度即可【$\frac{样品该基因的\ reads\ per \ million}{该数对应的行值}$】
2.2 FPKM (Fragments Per Kilobase Million)
FPKM和RPKM的定义是相同的,但適用於双端测序文库
FPKM会將配对比对到一个片段(fragment)上的两个reads计算一次,接下来的计算过程跟RPKM一样。
2.3 TPM (Transcripts Per Million)
同样是標准化测序深度和基因长度,TPM的不同在於它的处理顺序是不同的。即先考虑基因长度,再是测序深度。
-
第一步直接除以基因长度,得到reads per kilobase【$\frac{样品该基因的reads数}{该数对应的行值}$】
-
第二步標准化测序深度时,总的reads数要用第一步中除过基因长度的数值。【$\frac{样品该基因的\ reads\ per\ kilobase}{该样品所有基因\ reads\ per\ kilobase的和}$】
三、TPM更有优势的原因
下面,是考验你们数学功底的时候了,有没有看出来TPM分分钟完虐FPKM/RPKM?其实,只要我们在表3和表5下面多加一行你就能很轻鬆地看到区別了。
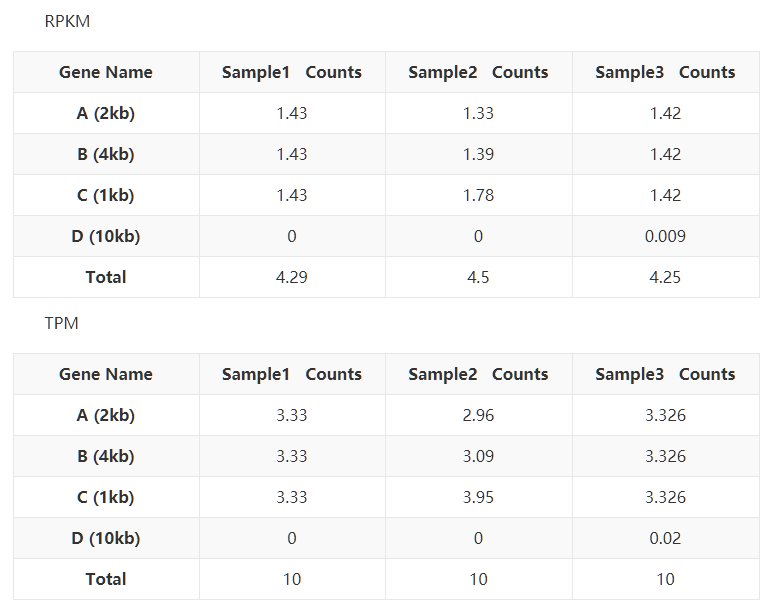
我们看到每个样本的TPM的总和是相同的,这就意味着 TPM数值能体现出比对上某个基因的reads的比例,使得该数值可以直接进行样本间的比较。
四、关键计算步骤

Kilobase:$10^3$
Million:$10^6$
综合数量级:$10^9$【不这样处理的话,RPKM/FPKM的值会非常小,不方便后续的处理和可视化,处理后的意义也相应变成per kilobase million】



© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END




暂无评论内容